
もし、全店舗全商品について来週の売上を一つずつ教えてくれる預言者がいたら、あなたはいくら払いますか?
Vertex Forecast なら、1 回のトレーニング&予測を大体 1 万円くらいでやってくれます。Google Cloud 提供の時系列予測をしてくれる AutoML(自動機械学習) の一種で、エンジニアがコードを書く必要もなく、ディープラーニングを使って高度な時系列予測をしてくれる優れモノ。
なんだか Google の回し者みたいな書き出しになってしまいましたが、自分で使ってみて本当に素晴らしいと思ったのでぜひ共有させてください。
目次
いざ、Vertex Forecast を使いたい! 時に出てきた疑問
「トレーニング(学習)、予測、それぞれどのようなデータを準備すればいい?」
「予測には、目的変数以外の特徴量についても未来の数値が必要?」
「トレーニングに必要なデータの期間はどれくらい?」
「日別店別、日別店別商品別など、一度でどの粒度まで予測できる?」
など、色々な疑問が出てきました。
公式ドキュメントをじっくり読めば詳しく書いてあるのですが、一方で、初心者にはとっつきにくい面もあり、、、私が検証してわかった範囲ですが、この場を借りて Q&A 形式で共有します。よかったら参考にしてください。
なお、Vertex Forecast の基本的な操作方法やアウトプットなどは別記事にまとめてあるので、興味がある方はそちらも読んでくれると嬉しいです。
・2週間しか販売しない新商品を Vertex Forecast で時系列予測した結果
料金についても 1 回 1 万円と書きましたが、厳密にいうとデータ量やトレーニングの時間によって前後しますので、気になる人は料金計算ツールで試算してみてください。他の AutoML 系サービスと比較した記事も出しておりますので、そちらも良ければご参照下さい。
・AutoML Tables と Vertex Forecast の違い(利用シーン、アウトプット、料金)
トレーニング、予測、それぞれどのようなデータを準備すればいい?
答え:時系列識別子、タイムスタンプ、目的変数、特徴量を含むデータセット
そもそも、Vertex Forecast でトレーニング、予測をするのにそれぞれどのようなデータを用意すればいいのか。シンプルな例を示すとこんなイメージです。
<トレーニング用のデータ>
| 時系列識別子 | タイムスタンプ | 特徴量1 | 特徴量2 | 目的変数 |
|---|---|---|---|---|
| 商品名 | 販売日 | 販促有無 | 平均気温 | 売上金額 |
| 商品A | 2022/10/19 | 1 | 25 | 10000 |
| 商品A | 2022/10/20 | 1 | 26 | 11000 |
| 商品A | 2022/10/21 | 1 | 24 | 12000 |
| … | ||||
| 商品B | 2022/10/19 | 0 | 25 | 8000 |
| 商品B | 2022/10/20 | 0 | 26 | 9000 |
| 商品B | 2022/10/21 | 0 | 24 | 7000 |
| … |
<予測用のデータ>
| 時系列識別子 | タイムスタンプ | 特徴量1 | 特徴量2 | 目的変数 |
|---|---|---|---|---|
| 商品名 | 販売日 | 販促有無 | 平均気温 | 売上金額 |
| 商品A | 2022/11/19 | 0 | 12 | null |
| 商品A | 2022/11/20 | 0 | 13 | null |
| 商品A | 2022/11/21 | 0 | 10 | null |
| … | ||||
| 商品B | 2022/11/19 | 0 | 12 | null |
| 商品B | 2022/11/20 | 0 | 13 | null |
| 商品B | 2022/11/21 | 0 | 10 | null |
| … |
当てたい未来の数値(目的変数)は null にして、予測のインプットとします。
予測のアウトプットは、上記の null の部分に予測値が入った状態でかえってきます。
さて、ここで気になるのは、平均気温です。
通常、予測を実行するタイミングは販売日より前。販促有無は、予定が立っていれば正確にわかりますが、平均気温はどうすればいいのか。
予測には、目的変数以外の特徴量についても未来の数値が必要?
答え:必要です。できるだけ正確な予測値を入れる必要があります。
平均気温だったら、天気予報のデータを参照することになります。
言わずもがなですが、売上金額に対して平均気温の影響が大きい場合、予測精度も平均気温の予測精度に引っ張られます。
ちなみに、トレーニングで平均気温の列を入れてしまうと、予測時にも平均気温が必要になります。入れないとエラーになります。
Column prefix: . Error: Missing struct property: 平均気温
何時間も待って、出てきた結果が全件エラーは悲しすぎます。悲しい思いをするのは私だけで十分です。(←?)
トレーニングに必要なデータの期間はどれくらい?
答え:モデルのトレーニングに使用される列ごとに少なくとも 10 個の時系列
弊社でも一つの時系列識別子について 2 週間(14 個の時系列)で検証しましたが、かなり精度高く予測できました。
2週間しか販売しない新商品を Vertex Forecast で時系列予測した結果
これまでは、時系列予測というと、1 つの変数を長期間にわたり観察する航空機搭乗者数(一変量時系列データセット)が主流でした。
が、実際、ビジネスで扱われるのは多変量データセットです。商品は数週間で入れ替わり、長期間のデータはありません。さらに全国展開しているなら、数百、数千の店舗で数千、数万の商品の需要予測をしたいとき、一つずつ個別に予測するのは現実的ではありません。
そこで、多変量、短期間に対応した時系列予測が AutoML でできますよ、と言うのが Vertex Forecast です。秘訣はディープラーニングですが、詳しく知りたい方は公式へどうぞ。
日別店別、日別店別商品別など、一度のトレーニングでどの粒度まで予測できる?
答え:一発で、好きなだけ細かい粒度で予測できます。
ただし、時系列識別子に複数の列を指定することはできるのか? というと、できないです。
<トレーニング用のデータ(できない)>
| 時系列識別子 | 時系列識別子? | タイムスタンプ | 特徴量1 | 特徴量2 | 目的変数 |
|---|---|---|---|---|---|
| 商品名 | 店舗 | 販売日 | 販促有無 | 平均気温 | 売上金額 |
| 商品A | 店舗a | 2022/10/19 | 1 | 25 | 10000 |
| 商品A | 店舗a | 2022/10/20 | 1 | 26 | 11000 |
| 商品A | 店舗a | 2022/10/21 | 1 | 24 | 12000 |
| … | |||||
| 商品A | 店舗b | 2022/10/19 | 0 | 20 | 15000 |
| 商品A | 店舗b | 2022/10/20 | 0 | 19 | 16000 |
| 商品A | 店舗b | 2022/10/21 | 0 | 18 | 17000 |
| … | |||||
| 商品B | 店舗a | 2022/10/19 | 0 | 25 | 8000 |
| 商品B | 店舗a | 2022/10/20 | 0 | 26 | 9000 |
| 商品B | 店舗a | 2022/10/21 | 0 | 24 | 7000 |
| … |
ここで、弊社でも何パターンか検証したので結果と合わせてご紹介します。
まずは、うまく行った例から。
商品数:3,800件
店舗数:50件
販売日:各商品、発売日から 2 週間程度(発売日は商品によって異なる)
販促有無:店舗、商品によって異なる
気温:店舗によって異なる
<トレーニング用のデータ>
| 時系列識別子 | タイムスタンプ | 特徴量1 | 特徴量2 | 目的変数 |
|---|---|---|---|---|
| 商品名 | 販売日 | 販促有無 | 平均気温 | 売上金額 |
| 商品A 店舗a | 2022/10/19 | 1 | 25 | 10000 |
| 商品A 店舗a | 2022/10/20 | 1 | 26 | 11000 |
| 商品A 店舗a | 2022/10/21 | 1 | 24 | 12000 |
| … | ||||
| 商品A 店舗b | 2022/10/19 | 0 | 20 | 15000 |
| 商品A 店舗b | 2022/10/20 | 0 | 19 | 16000 |
| 商品A 店舗b | 2022/10/21 | 0 | 18 | 17000 |
| … | ||||
| 商品B 店舗a | 2022/10/19 | 0 | 25 | 8000 |
| 商品B 店舗a | 2022/10/20 | 0 | 26 | 9000 |
| 商品B 店舗a | 2022/10/21 | 0 | 24 | 7000 |
| … |
<予測結果>
赤が予測値、青が実測値。
全商品全期間のサマリ
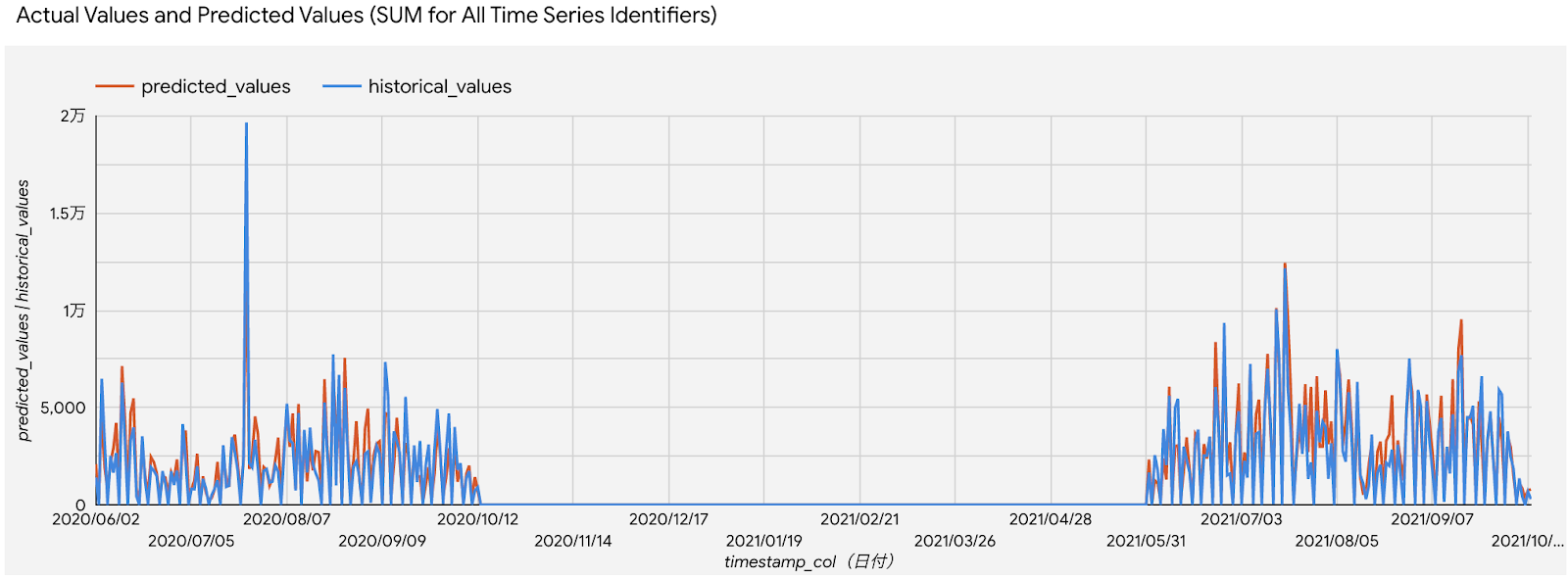
通常、予測は未来に対して行うので実測値はわからないのですが、今回は精度検証のため、過去の実測値をnullに置換して予測のインプットとしております。
グラフは全商品全期間のサマリですが、予測は個別(時系列識別子ごと)に行われているので、以下のように、ある商品についてピックアップすることもできます。

少し予測値の方が低く出ていますが、休配日を正確に読めているとか、いい感じです。
次に、NGだった例をまとめて紹介します。
<NGパターン①店舗を特徴量の一つ(属性)として読ませた場合>
| 時系列識別子 | タイムスタンプ | 特徴量1 | 特徴量2 | 特徴量3 | 目的変数 |
|---|---|---|---|---|---|
| 商品名 | 販売日 | 販促有無 | 平均気温 | 店舗 | 売上金額 |
| 商品A | 2022/10/19 | 1 | 25 | 店舗a | 10000 |
| 商品A | 2022/10/20 | 1 | 26 | 店舗a | 11000 |
| 商品A | 2022/10/21 | 1 | 24 | 店舗a | 12000 |
| … | |||||
| 商品A | 2022/10/19 | 0 | 20 | 店舗b | 15000 |
| 商品A | 2022/10/20 | 0 | 19 | 店舗b | 16000 |
| 商品A | 2022/10/21 | 0 | 18 | 店舗b | 17000 |
| … | |||||
| 商品B | 2022/10/19 | 0 | 25 | 店舗a | 8000 |
| 商品B | 2022/10/20 | 0 | 26 | 店舗a | 9000 |
| 商品B | 2022/10/21 | 0 | 24 | 店舗a | 7000 |
| … |

ダメでした。試しに、店舗を一つに絞った状態でトレーニング、予測を行ったら普通にうまくいきました。
1 組の時系列識別子とタイムスタンプに対し、特徴量や目的変数が複数存在すると、ダメです。
例えば、 2022/10/19 の商品 A の売上金額は、10000 円(店舗a)と15000 円(店舗b)の2つが存在しています。Vertex Forecast からすれば、どっちやねん、という話なのかなと。
<NGパターン②店舗を特徴量の一つ、かつ「重み列」として読ませた場合>
| 時系列識別子 | タイムスタンプ | 特徴量1 | 特徴量2 | 特徴量3 (重み列) | 目的変数 |
|---|---|---|---|---|---|
| 商品名 | 販売日 | 販促有無 | 平均気温 | 店舗 | 売上金額 |
| 商品A | 2022/10/19 | 1 | 25 | 店舗a | 10000 |
| 商品A | 2022/10/20 | 1 | 26 | 店舗a | 11000 |
| 商品A | 2022/10/21 | 1 | 24 | 店舗a | 12000 |
| … | |||||
| 商品A | 2022/10/19 | 0 | 20 | 店舗b | 15000 |
| 商品A | 2022/10/20 | 0 | 19 | 店舗b | 16000 |
| 商品A | 2022/10/21 | 0 | 18 | 店舗b | 17000 |
| … | |||||
| 商品B | 2022/10/19 | 0 | 25 | 店舗a | 8000 |
| 商品B | 2022/10/20 | 0 | 26 | 店舗a | 9000 |
| 商品B | 2022/10/21 | 0 | 24 | 店舗a | 7000 |
| … |

ダメですね。重み列はあくまでもバイアスを減らす目的で使われるものなので、店別商品別で予測した場合は、やはり商品と店の情報は時系列識別子に含ませる必要があります。
弊社は Google パートナーなこともあり、無料枠内で色々と試すことができたのを幸いに、ここぞとばかりに検証してみました。
ここまで読んでくださってありがとうございます。少しでも、みなさまの参考になれれば幸いです。
まとめ
- 時系列識別子、タイムスタンプ、目的変数は一意にする必要がある
- トレーニングで使った特徴量は、予測時にnullにすることはできない
- 時系列識別子列とタイムスタンプ列は、それぞれ1列しか指定できない
参考(公式ドキュメント)
表形式のトレーニング データを作成するためのベスト プラクティス
階層集計で予測バイアスを低減する
API AutoML Bard BigQuery BigQuery ML Bing ChatGPT Cloud Endpoints DWH DX GAS Generative AI Google Apps Script Google Cloud Google Form Google Workspace IT組織 Outlook PDF Python ReportLab selenium Snowflake VertexAI Vertex Forecast スクラッチ スクレイピング スプレッドシート セミナー ソトミル トレーニング バッチ予測 世界は女性とデジタルが救う 内製化 女性活躍 技術 時系列データ分析 業務効率化 機械学習 特徴量エンジニアリング 生成AI 自動化 評価指標 説明可能なAI 需要予測