
以前、Vertex Forecast を使ってノーコードでモデル作成、時系列予測をする方法を徹底解説シリーズで色々と解説したのですが、「で、結局どうすれば精度が上がるの?」という疑問については、データセット次第、ユースケース次第なところが大きく、調べてもはっきりしないと思います。
なので、今回はあくまで参考値ですが、個人的に試してみてこれは効いたな、これはいじってもあんまり変わらなかった(むしろ精度悪化した)な、というのをまとめてみました。
他にも、実際に触る中で疑問に思ったことなどをQ&A形式にしてあります。
目次
Vertex Forecast でモデルの精度アップに最も効く方法、条件
「何をどう変えたら Vertex Forecast でのモデル作成で精度をよくできるのか?」について、備忘メモを残しておきます。
| タイミング | 方法、条件 | 説明 | 例 | 精度への影響度 |
| ⓪データ前処理(特徴量エンジニアリング) | クレンジング | 欠損や不正を修正する | null→ダミー値 | ◯ |
| 統合 | 複数のデータソースからデータを収集 | 日付・住所に天気を紐付ける | ◯ | |
| 期間の絞り込み、追加 | トレーニングデータに含める期間、予測する期間 | 過去3ヶ月分から先1ヶ月を予測 | ◎ | |
| 変換 | 機械学習で処理しやすい形式に変換する | テキスト→数値 | × | |
| 正規化、標準化 | データのスケールを揃える | 0〜1に変換、平均0分散1に変換 | × | |
| 次元削減 | 特徴量の数を減らす | カテゴリ列に変換、相関が強い特徴量同指を統合 | × | |
| ①トレーニング | トレーニング方法 | AutoML、Seq2seq+、TFT、カスタムから選択※ | – | ◯ |
| コンテキスト期間 | Vertex Forecast モデルが予測パターンを検索する期間 | 別記事を参照 | △ | |
| 特徴列(説明変数) | 特徴タイプや予測時に利用可能かなどを設定 | △ | ||
| 重み列 | あるデータ群を強調する | ◎ | ||
| 最適化の目標 | どの評価指標を最適化するか選択する(RMSE、MAE、RMSLE、WAPE、分位点損失) | ◯ | ||
| 階層予測 | データ階層ごとに学習を行う | ◎ |
複雑な時系列予測に最適とされるトレーニング方法「TFT」とは
TFT(Temporal Fusion Transformer)とは、「入力されたデータのどこに注目すべきか」を動的に特定する仕組み( = Attention メカニズム)を用いたTransformer モデルを用いて長距離の依存関係をキャプチャする機械学習アーキテクチャです。Attention メカニズムでは、入力データと出力データの間の類似度を計算し、類似度が最も高い部分が最も注目すべき部分と見なされます。自然言語のディープラーニングの要素技術の一つで、主に機械翻訳、テキスト要約などで応用されています。
TFTが有効なケースは以下の通りです。
- 複数の共変量からの情報を統合する必要がある時間系列予測タスク
- 時間的依存関係とイベントを考慮する必要がある時間系列予測タスク
- 解釈可能な予測が必要な時間系列予測タスク
具体的には、製品の売上予測、エネルギーの消費予測、交通量予測などで、どの共変量が最も重要であるか、および予測にどのように影響するかを理解するのに役立ちます。
ただ、過去記事の例では前処理で次元削減して特徴量の数を 11 まで削ってあったためか、AutoMLの方が精度が高かったです。
数十、数百という特徴量の数なら、前処理なしでTFTを試すのも一つの選択肢かと思います。
Vertex Forecastを使う上でのQ&A
Q:特徴量の数は多ければ多いほどいい? どれくらいの特徴量数が適正なの?
A:特徴量が多すぎると、モデルの精度が低下する可能性があります。特徴量の数が適正かどうか判断するには、一度モデルを作成し、Vertex AIのメニューの「Model Registry」で「特徴量の重要度」を確認します。重要度の低い特徴量はモデルのトレーニングに必要ないので除外できます。
一般的に、特徴量の適正な数は、使用する機械学習モデルやデータセットによって異なります。データセットが大きいほど、モデルはより多くの特徴量を学習でき、データセットが複雑であるほど、モデルはより多くの特徴量を必要とします。
Q:一般的な機械学習における前処理(次元削減、正規化、標準化など)は必要?
A:公式では必要、とされています、が、、、
自分で色々と試した結果、Vertex Forecast においては、一般的な機械学習の前処理(特徴量エンジニアリング)はほとんど不要なのでは、と思いました。正規化や次元削減などの前処理は、むしろやらない方が精度が高かったです。
ある案件で、まずはベンチマークとして最初に生データをほぼそのまま(欠損値処理など最低限のみやった状態で)トレーニングしたものを提示し、その後は少し時間をかけて前処理やパラメータ調整する中でよくなっていく工程を見せてアピールしようとしたのですが、前処理するとかえって精度が悪化するという事態に陥って結構テンパりました。。
Q:時系列予測の精度を評価するための適切な指標は?
A:時系列モデルの評価指標としてよく使われるものは以下の通り。実際はケースバイケースなことが多く、お客様のビジネス目標と合わせて相談になります。
- 平均絶対誤差(MAE):予測と実際の値の絶対値の平均
- 二乗平均平方根誤差(RMSE):予測と実際の値の平方の平均の平方根
- 平均絶対パーセント誤差(MAPE):予測と実際の値の絶対値の平均を実際の値の平均で割ったもの
- 平均二乗パーセント誤差(MSE):予測と実際の値の平方の平均を実際の値の平均で割ったもの
- シャープe:予測の正解率と不正解率を調整した尺度
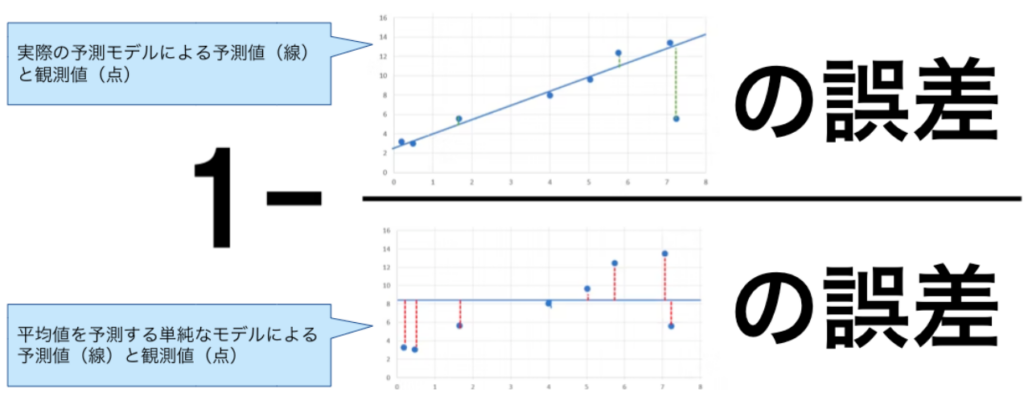
Q:時系列予測の精度の評価に、決定係数(R^2)は適切か?
A:決定係数(R^2)は回帰モデルの評価に使われる指標で、時系列モデルの評価には適しません。なぜなら、時系列データは時間的な相関関係を持ち、同じ観測値が繰り返される可能性があるため、R^2はそのような時間的な相関関係を反映しきれないためです。
R2 乗( R^2 )は、観測値と予測値間のピアソン相関係数の 2 乗です。予測値と観測値の誤差が、平均値を予測する単純なモデルと比較してどれだけ小さいかを示します。常に平均値と比較し、モデルの導入により「どれだけ当てはまりがよくなったか」を表します。
まとめ
- Vertex Forecast では前処理(次元削減、正規化、標準化など)はあまり効果なし
- 階層予測は非常に効果的
- 特徴量の数が多い時は、TFTでトレーニングしてみるのも一手
- 時系列モデルの評価指標に決定係数(R^2)は不適切なので注意
API ARIMA AutoML Bard BigQuery Bing ChatGPT Cloud Endpoints Cloud Storage DWH EBPM GAS Generative AI Google Apps Script Google Cloud Google Form Google Workspace IT組織 Outlook PaLM PDF Python ReportLab selenium Statsmodels STL VertexAI Vertex Forecast スクラッチ セミナー ソトミル トレンド分析 トレーニング バッチ予測 世界は女性とデジタルが救う 女性活躍 技術 時系列データ分析 業務効率化 機械学習 特徴量エンジニアリング 生成AI 自動化 評価指標 需要予測