
以前ご紹介した、Vertex Forecast を使ってノーコードでモデル作成、時系列予測をする方法を徹底解説では触れなかった、モデルのトレーニング時の各種設定やパラメータなどについて解説します。
コンテキスト期間や、重み列、最適化の目標(RMSE、MAEなど)、階層予測について、どういう値にするとどんな結果になるのか、実際の例を使いながらわかりやすく紹介できればと思います。
実際に業務で使っていく際は必須だと思うので、よかったらご参考になさってください。
※ノーコードで機械学習したいユーザ向け、Google Cloud の 画面(GUI)を使ってモデル構築する際の設定項目に関する記事です。
目次
Vertex Forecast モデルのトレーニング(モデル詳細)
Vertex Forecast は AutoML 系の機械学習サービスなので、ユーザがいじれる項目は決まっています。モデル詳細では、以下の項目になります。
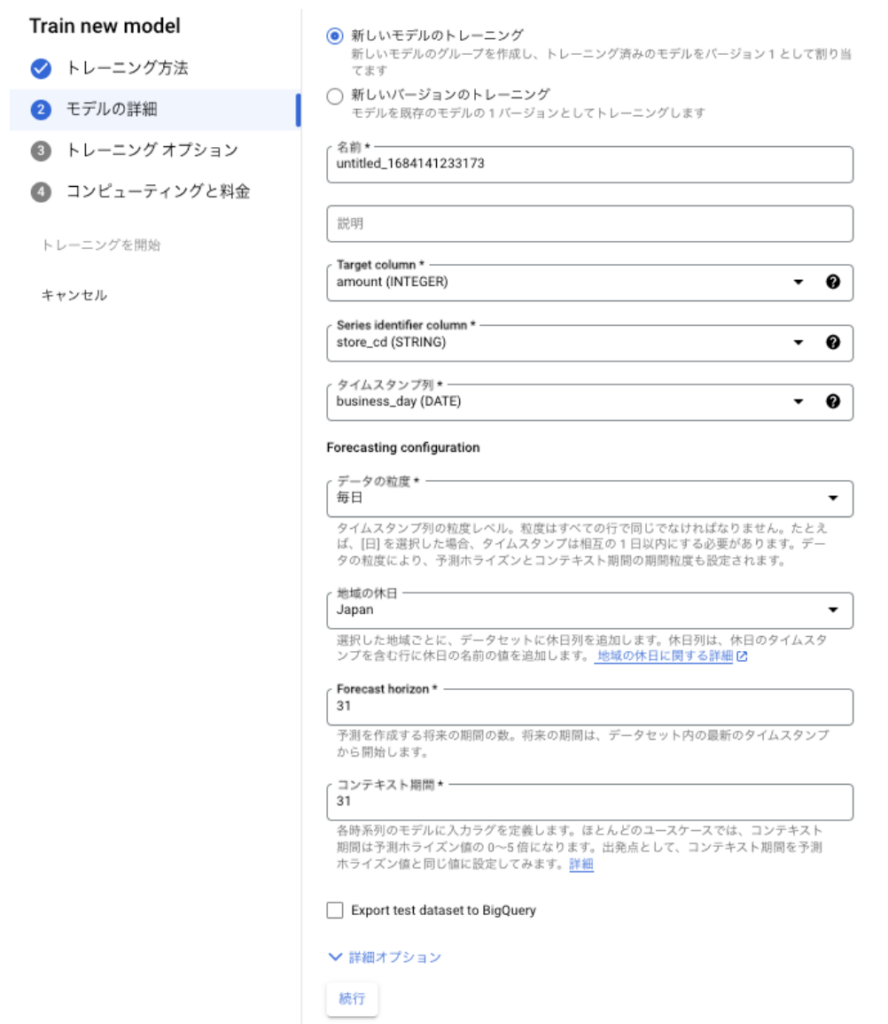
- Target Column(ターゲット列):予測したい項目(例:売上金額)
- Series identifier column(時系列識別子列):●●ごとに予測したい、の●●の部分。(例:店舗コード)
- タイムスタンプ列:日別ならYYYY-MM-DDの列。年、月、時間、秒なども可。学習データの粒度に依存する。(例: 営業日)
- データの粒度:日別なら「毎日」
- 地域の休日:日本のデータなら「Japan」
- Forecast horizon :予想したい期間。(例:日別で、先 1ヶ月間の予測なら 30 or 31)
- コンテキスト期間:モデルが予測パターンを検索する期間。基本は Forecast horizon と同じ値でOK。
<コンテキスト期間>
コンテキスト期間は、Vertex Forecast モデルが予測パターンを検索する期間です。
モデルは、コンテキスト期間中のデータを使用して、予測に使用するトレンドと季節性を特定します。つまり、コンテキスト期間が長いほど、モデルはより多くのデータでトレーニングされますが、計算コストも高くなります。コンテキスト期間が短いほど、モデルは計算コストが低くなりますが、精度も低くなる可能性があります。
コンテキスト期間の最適な長さは、データとビジネス目標によって異なり、いろんな長さで試してもらうしかありません。具体的には、まずは Forecast horizon の値と同じもので作ってみて、次は倍にする、次は半分にする、などして精度がどうなるかをみながら調整していきます。
私が色々試した結論としては、Forecast horizon と同じ値でいいかなと。過去データがコロナ禍で特殊な動きをしていた、というのも大きいと思いますが、コンテキスト期間を長期(例えば日別データで90日)にすると精度はかえって悪化しました。
左:コンテキスト期間30日、右:コンテキスト期間90日

季節性を見るなら 1 年分かな、と思い 365 で試しもしましたがもっと悪化したと記憶しています。コロナ期間を除くデータで 1 年分揃えばまた話は違ってくるかもしれませんが、長期(1年以上)のデータを学習させる試みはひとまず諦めました。
Vertex Forecast モデルのトレーニング(トレーニング オプション)
次に、トレーニングオプションのページでいじれる項目について解説します。
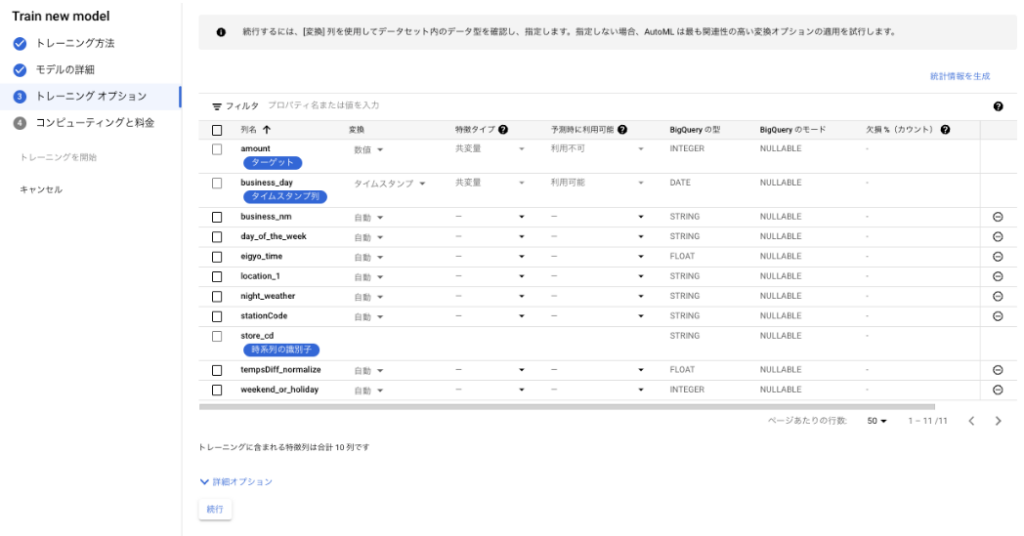
トレーニングオプションでは、トレーニングデータセットの列名が表示されています。
必須項目は、「特徴タイプ」のみで、「属性」か「共変量」をセットします。
<特徴列(説明変数)の設定に関する補足>
・変換
デフォルト「自動」になっていますが、カテゴリ、テキスト、タイムスタンプ、数値から選択可能です。フラグ(0,1)など、数値だけどカテゴリとして認識させたい、というケースではカテゴリを選択しておきます。
なお、月の列(12月なら「12」と入っている)のような場合は、数値ではなくカテゴリとして扱う必要があります。月は連続した値ではなく一連の離散値なのですが、数値として扱ってしまうと、月が連続した値であると仮定されてしまいます。
・特徴タイプ
属性とは、時系列の期間中に変化しない静的な機能です(たとえば、アイテムの色や商品の説明など)。
共変量とは、時間の経過とともに変化することが見込まれる外生変数です(たとえば、天気予報、休日、遅延値など)。
・予測時に利用可能
予測時に利用できる共変量は主要なインジケーターです(たとえば、休日、予定されたプロモーション、イベントなど)。予測を作成する際は、予測ホライズンの各ポイントにこの列の値を指定する必要があります。
予測時に利用できない共変量には、例として天気などがあります。予測の作成時に、これらの特徴の値を指定する必要はありません。
・欠損(%)カウント
各列の null または欠損値の割合です。
目安として 10 % を超えるようなら、ダミーデータで埋めるなり列ごと削除するなり、何らかの前処理をしておいた方がいいとされています。
Vertex Forecast モデルのトレーニング(トレーニング オプション(詳細オプション))
さらに画面下部にある「詳細オプション」のドリルダウンで表示される項目には、重み列や最適化の目標、階層予測などがあります。
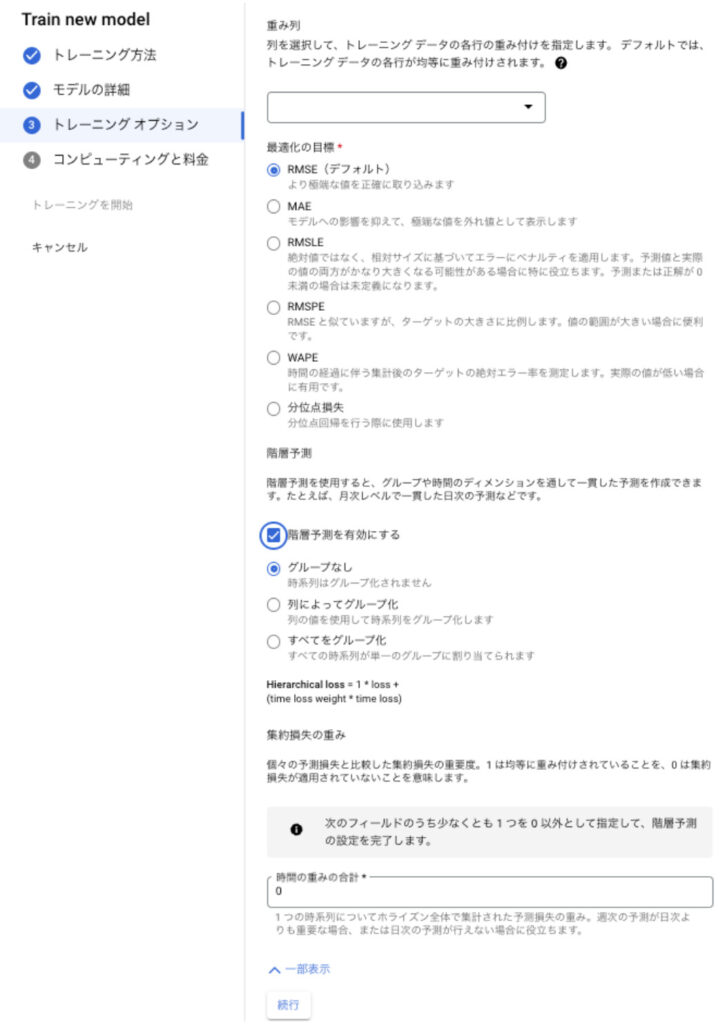
<重み列>
重み列は、不均一なデータセット(カテゴリA、カテゴリBは100行ずつあるのにカテゴリCは10行しかない)で、少数派のデータ群を強調したいという時、重み列を使います。
使い方は、トレーニングデータに重み列を追加して 0 ~ 10000 の数値を指定し、上記の画面で重み列を選択するだけです。
数値の決め方は、ひとまずデータの割合の逆数でやってみて様子を見ます。
カテゴリA:100行
カテゴリB:100行
カテゴリC:10行
計210行
上記のデータセットなら、各カテゴリの重み列は、全件数 / カテゴリの件数 になるイメージです。
カテゴリAの重み:210行 / 100行 = 2.1
カテゴリBの重み:210行 / 100行 = 2.1
カテゴリCの重み:210行 / 10行 = 21
ちなみに、このような重み付けは不均一なデータセットの前処理の定番で、他にも以下のようなものがあります。
- オーバーサンプリング:少数派のデータ群をコピペで増幅させてデータセットに追加する
- SMOTE:少数派のデータ群を機械学習を使った合成で増幅させてデータセットに追加する
- アンダーサンプリング:多数派のデータ群からデータを削除して均一にする
- 重み付け:少数派のデータ群に高い重みを割り当てて、無視されないようにする
<最適化の目標>
画面に書いてある説明の通りなのですが、読んでもピンとこないかもしれないので補足も追記します。
| 概要 | 使い所 | |
| RMSE | 予測と実際の値の平方の平均の平方根 | 精度を重視する時 |
| MAE | 予測と実際の値の絶対値の平均 | 精度と解釈の容易さを重視する時 |
| RMSLE | 対数変換された予測と実際の値の平方の平均の平方根 | 指数関数的な傾向を持つデータで精度を重視する時 |
| RMSPE | 予測と実際の値のパーセント誤差の平均の平方根 | 元の値が大きいデータで精度を重視する時 |
| WAPE | 予測と実際の値の重み付けされた絶対値のパーセント誤差の平均 | さまざまな値の重要度を考慮する必要がある場合、または精度と解釈の両方を重視する時 |
| 分位点損失 | 指定された分位点における予測と実際の値の差たとえば、50パーセンタイルの分位点損失は、予測と実際の値の中央値の差になる | 特定の分位点の精度を重視する時 |
まぁ精度が一番なケースがほとんどだと思うので、よくわからなければデフォの RMSE でいいと思います。弊社でも検証を兼ねて一通り試しましたが、最終的にはRMSEに落ち着くことが多いです。
<階層予測 >
例えば、全国に店舗を展開している飲食チェーンの場合は、業態Aでは500店舗、業態Bでは300店舗、業態Cでは10店舗、のように、データが偏っていることがあります。
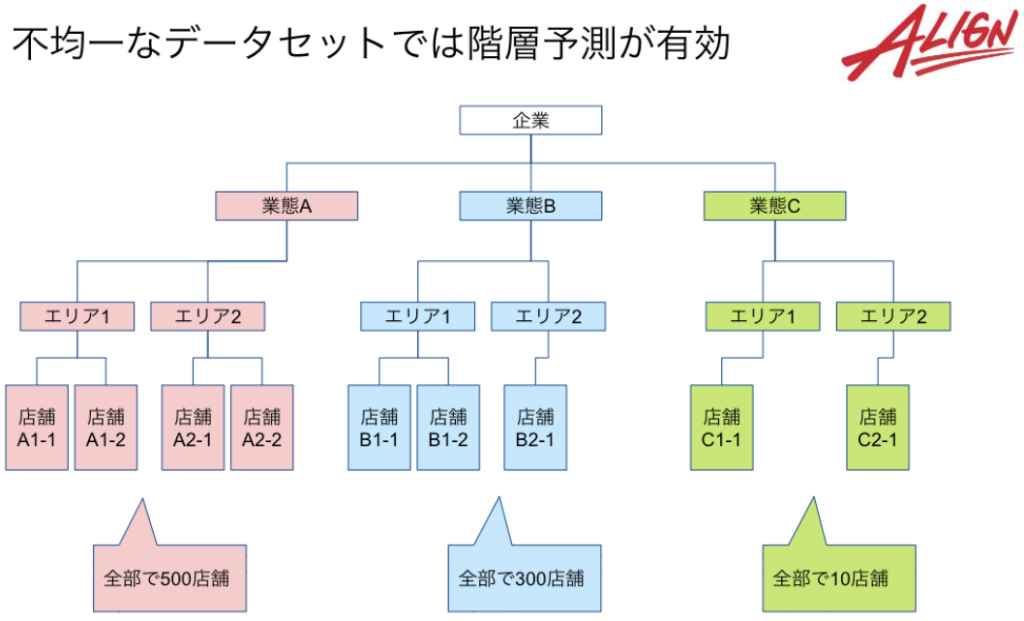
このような場合、店舗ごとの立地や営業時間、曜日、天気などももちろん売上に影響するのですが、それ以前に異なる業態の店舗も一緒に学習させていいのかという疑問が出てくると思います。
通常、業態(安くて量が多い、高級志向など)によって店舗の売上が全然違う、のような場合は業態ごとにモデルを分けるのが一般的ですが、Vertex Forecast には、階層予測機能がありデータの階層構造を考慮するため、1モデルで全業態の店舗の予測が可能で、非常に安上がりです。
内部の動き的には、階層構造を考慮して先に「業態」ごとに予測した後に店舗ごとの予測を行っているようです。
階層予測の数値は何倍にすべきかというと、目安として、ひとまず、10倍からスタートして、30倍にしたらどうか、50倍にしたらどうか、と調整していく感じになります。
例として、階層予測をせずにデフォルトのままトレーニングしたモデルで予測した場合と、業態列を30倍に指定してトレーニングしたモデルで予測した場合の予実比較を以下に載せておきます。赤線が予測値、青線が実績値です。実際は日別店舗別に予測値が出ていますが、全店グラフにするとぐちゃぐちゃになるので各合計をグラフ描画しています。
全体)左:階層予測なし、右:階層予測あり

業態別にグラフ化してみると、こんな感じです。
業態別)左:階層予測なし、右:階層予測あり
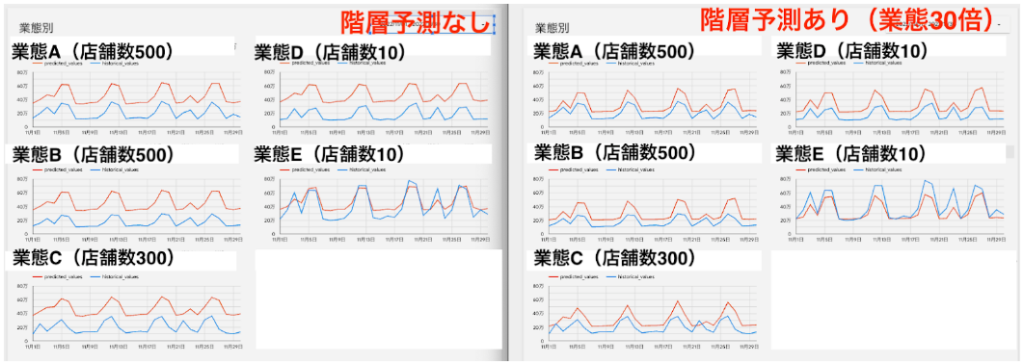
※違いをわかりやすくするためにあえて精度の低い結果を掲載しています。
今回のような、業態によって店舗数が大きく異なる、というケースでは階層予測は非常に有効でした。実際の業務でも学習データが均一な方が稀だと思うので、まだ試したことがないという方は、積極的に活用してみてください。
まとめ
- コンテキスト期間とは、モデルが予測パターンを検索する期間
- 重み列は、不均一なデータセットで少数派のデータ群を強調する際に利用する
- 階層予測は、階層構造を持つデータセットの予測に非常に有効
API ARIMA AutoML Bard BigQuery Bing ChatGPT Cloud Endpoints Cloud Storage DWH EBPM GAS Generative AI Google Apps Script Google Cloud Google Form Google Workspace IT組織 Outlook PaLM PDF Python ReportLab selenium Statsmodels STL VertexAI Vertex Forecast スクラッチ セミナー ソトミル トレンド分析 トレーニング バッチ予測 世界は女性とデジタルが救う 女性活躍 技術 時系列データ分析 業務効率化 機械学習 特徴量エンジニアリング 生成AI 自動化 評価指標 需要予測