
以前、Vertex Forecast の基本的な使い方や結果の見え方について、「2週間しか販売しない新商品を Vertex Forecast で時系列予測した結果」という記事にまとめました。
今回は、具体的な例を用いて、どのタイミングで、どのようにデータセットを用意する必要があるのか、全体の流れ、評価の見方等について、実際に使う時に迷いそうなポイントを拾いつつ、もう少し詳しく解説していきたいと思います。
Vertex Forecast を使った予測の全体の流れ

全体の流れは、⓪準備、やりたいことの整理、①トレーニング(モデル作成)、②バッチ予測、③予実比較・評価です。
⓪準備、やりたいことの整理
データセットなど、手持ちのデータを準備・整理し、やりたいことを明確にします。
①トレーニング(モデル作成)
- トレーニング用、テスト用、テスト答え用のデータセットを作る
- Vertex AI に トレーニング用のデータセットを取り込む
- トレーニング用を使って Vertex Forecast でトレーニング(モデル作成)を行う
②バッチ予測
上記で作成したモデルと、テスト用データセットを使ってバッチ予測を行う
③予実比較・評価
上記で作成された予測結果と、テスト答え用データセットを使って予実の比較、評価を行う
※グラフ化は Looker Studio が使いやすいです。
⓪準備、やりたいこと
A. データセットの準備
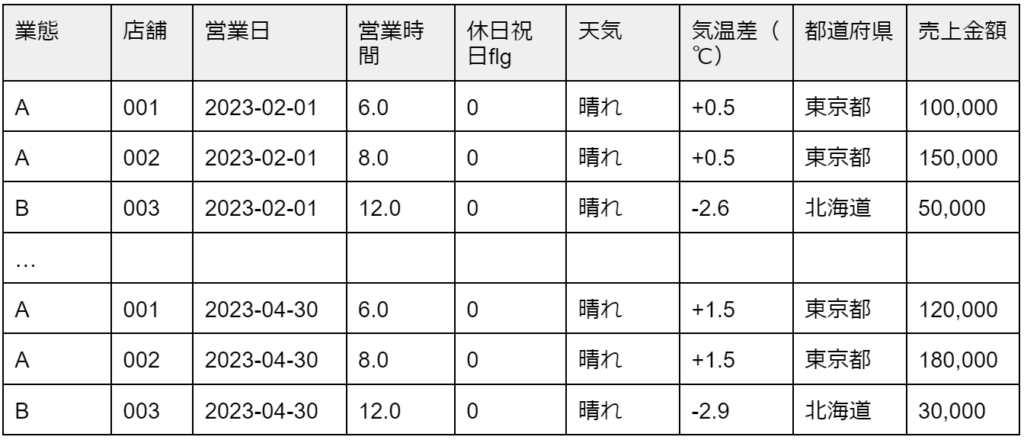
日別店舗別のデータセットの例として、店舗を全国展開しており、業態も複数あるケースだと、こんなテーブルになると思います。
期間は2023年2月〜4月の3ヶ月分があるとします。
[表1] 日別店別の売上(2〜4月分)
B. やりたいこと
4月末時点で、先1ヶ月間(5月分)の日別店舗別の売上を予測したい
[表2] 日別店別の売上(5月分)
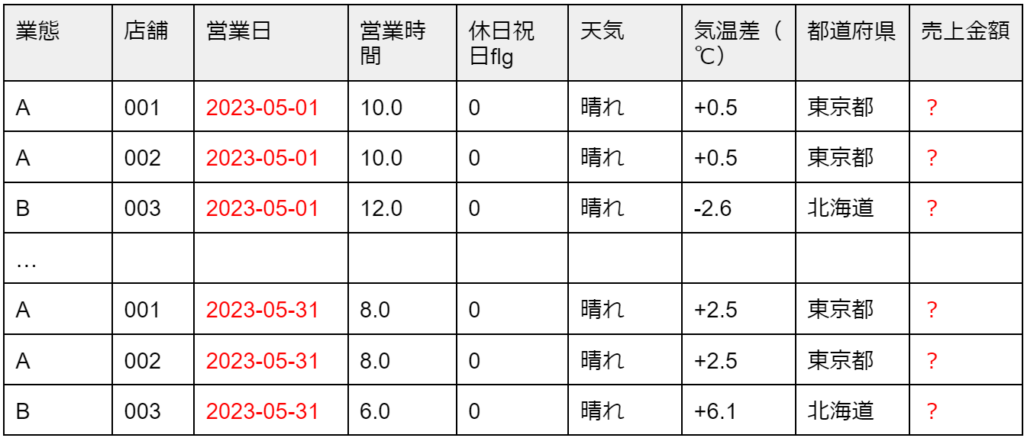
※5月の営業時間は営業スケジュールを、天気や気温は4月末時点での天気予報データを使います。
なお、休日祝日フラグや、天気や気温差は、弊社「ソトミル」で付与したデータです。リアル店舗の場合、天気や気温などの気象情報は売上に大きな影響を与えるため、付与した方が学習結果がよくなるケースが多いです。他にも、野球観戦やお花見のようなイベントデータも結合し、学習させることができます。店舗の住所があれば簡単に結合できるので、興味ある方はお問い合わせください。
C. データセットの要件、ターゲット列、時間列、時系列識別子列を確認
Vertex Forecast を使って学習(モデル構築・評価)、予測を行う場合、データセットは以下の要件を満たす必要があります。
- 100 GB 以下
- 列数は 2~1,000 列
- ターゲット列は 1 列
- ターゲット列は数値のみ
- 行数は 1,000~100,000,000 行
- 時間列のすべての行に値が入っている
- 時系列識別子列の行に値が入っている
ターゲット列、時間列、時系列識別子列って何かというと、今回やりたいことは「日別店舗別の売上金額」なので、それぞれ以下の列が該当します。
ターゲット列:「売上金額」
時間列:「営業日」
時系列識別子列:「店舗コード」
①トレーニング(モデル作成)
1. トレーニング用、テスト用、テスト答え用のデータセットを作る
準備したデータセットを元に、トレーニング用、テスト用、テスト答え用のデータセットを作成します。データセットはBigQueryにテーブルとして用意します。
以下は各テーブルのイメージです。
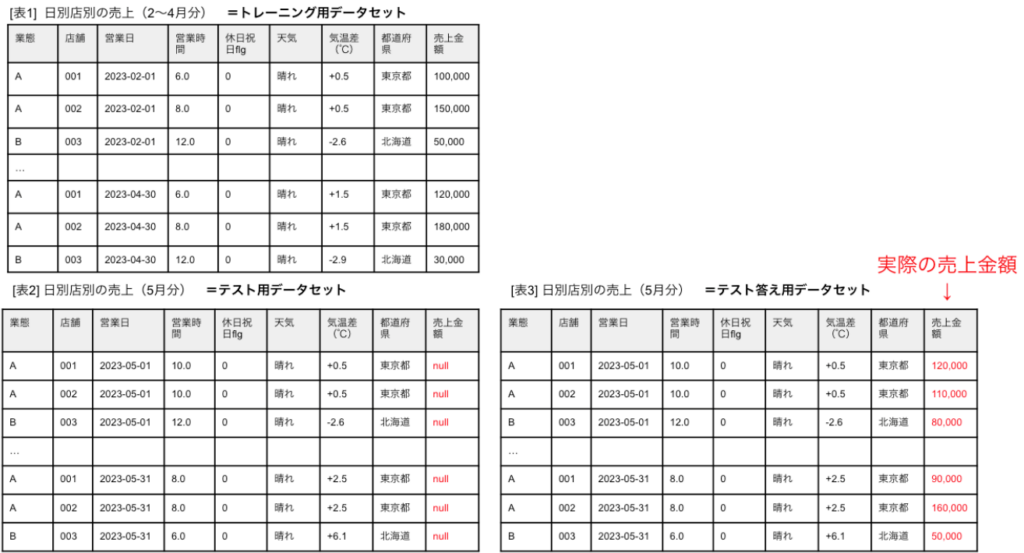
注意点としては、3つのテーブルのカラム、データ型は全て一致している必要があるということ。例えば、5月の天気がわからないから、という理由で表2、表3の「天気」列を削除したりすると、バッチ予測時にエラーで落ちてしまいます。(ただし、この辺の仕様はアプデで変わる可能性もあるので、2023/05/15時点での情報とご認識おきください)
・トレーニング用データセット
今回はひとまず、2〜4月の3ヶ月分(表1)をそのままトレーニングデータとします。
件数が多すぎたり、あるいは、もっと過去のデータを学習させたいなどの場合は、必要に応じてデータを切り出しましょう。
・テスト用データセット
5月分(表2)を作成します。これは予測対象、つまり未来のデータなのでまだ実績がありません。天気や気温、営業時間なども予報や計画の数値を入れていきます。
注意点として、ターゲット列(売上金額)は全てnullとしておく必要があります。
・テスト答え用データセット
表2の、ターゲット列(売上金額)に実際の値を入れます。
4月末時点ではわからないと思うので、5月末に実績データが揃ったタイミングで行います。
なお、Vertex Forecast が実運用で使えるかどうか試したい、という段階であれば、すでに実績のある期間をあえて予測させて、予実比較を行います。
例えば、2〜3月までの2ヶ月間のデータをトレーニング用とし、4月分を切り出してテスト答え用、4月分のテスト答え用をコピーして売上金額だけnullにすればテスト用のデータセットが作成できます。
2. Vertex AI に トレーニング用のデータセットを取り込む
BigQueryに作成したトレーニング用のデータセット(テーブル)をVertex AIに取り込みます。
Vertex AIのメニューにある「データセット」画面を開き、「作成」をクリック
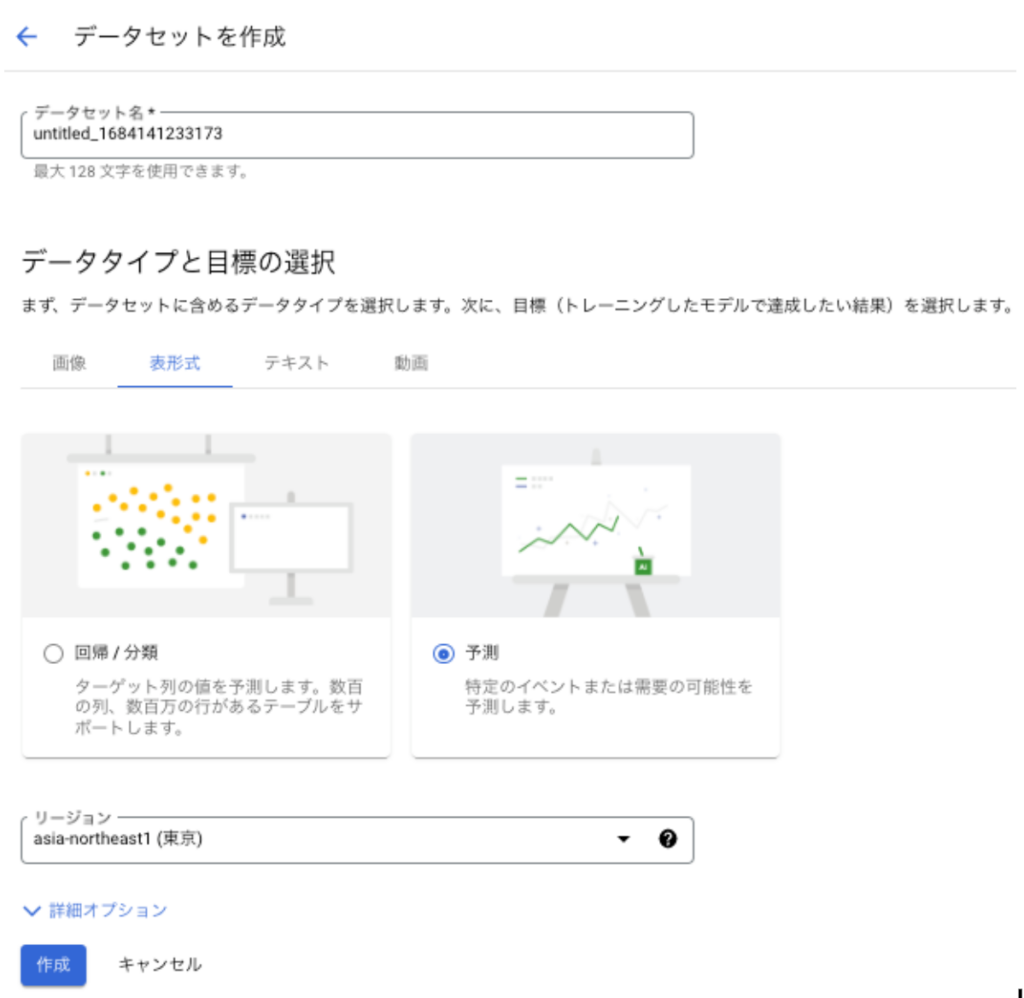
データセット名をつけて、「表形式」>「予測」を選択して「作成」
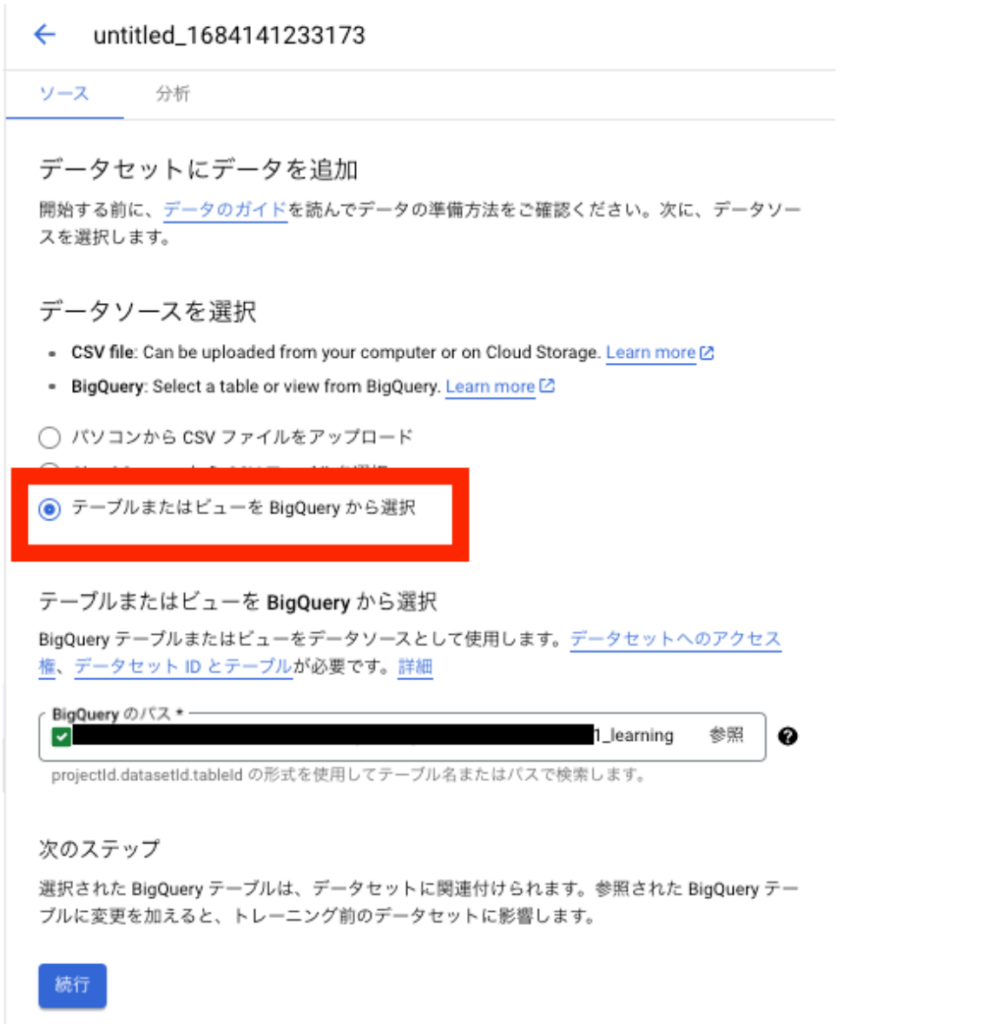
「データソースを選択」で「テーブルまたはビューを BigQuery から選択」を選択し、トレーニング用テーブルのフルパスを入力します。(参照から選べば勝手にフルパス入ります)
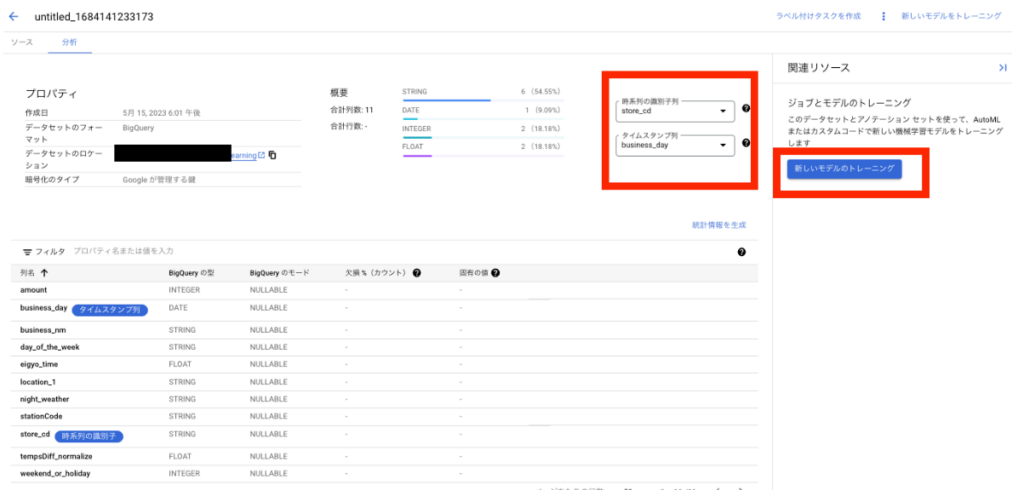
時系列の識別子列に「店舗コード」、タイムスタンプ列に「営業日」を指定し、「新しいモデルのトレーニング」をおす。
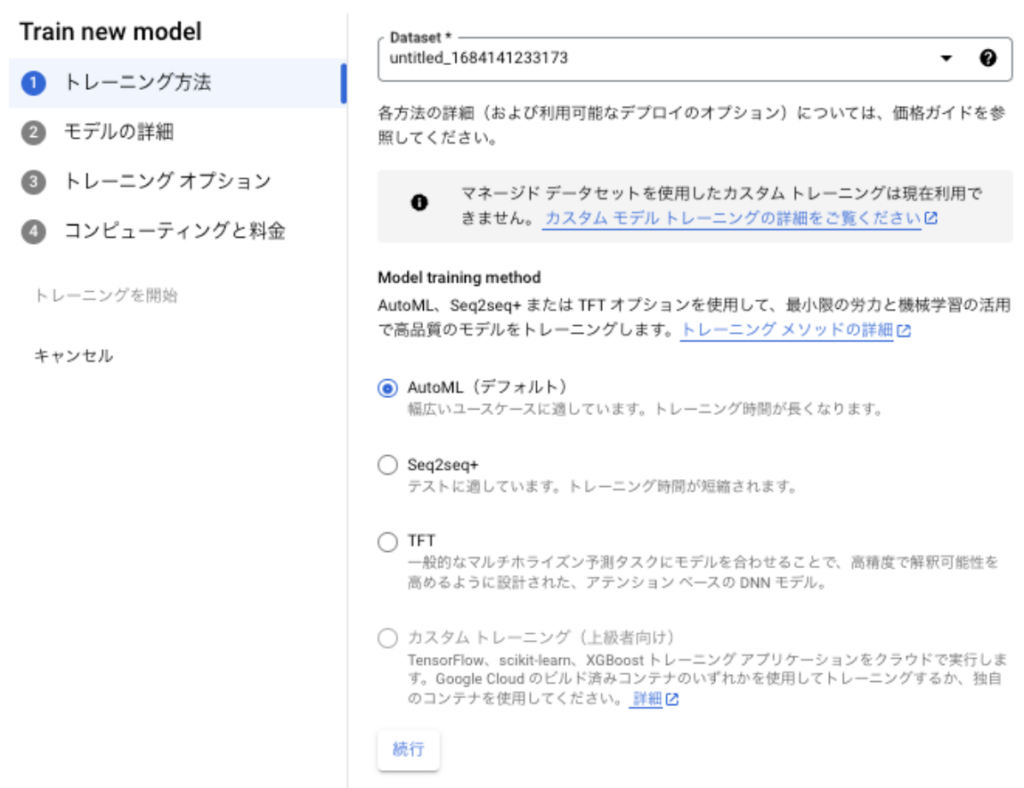
トレーニング方法を選択します。まずはデフォルトのAutoMLでOK。
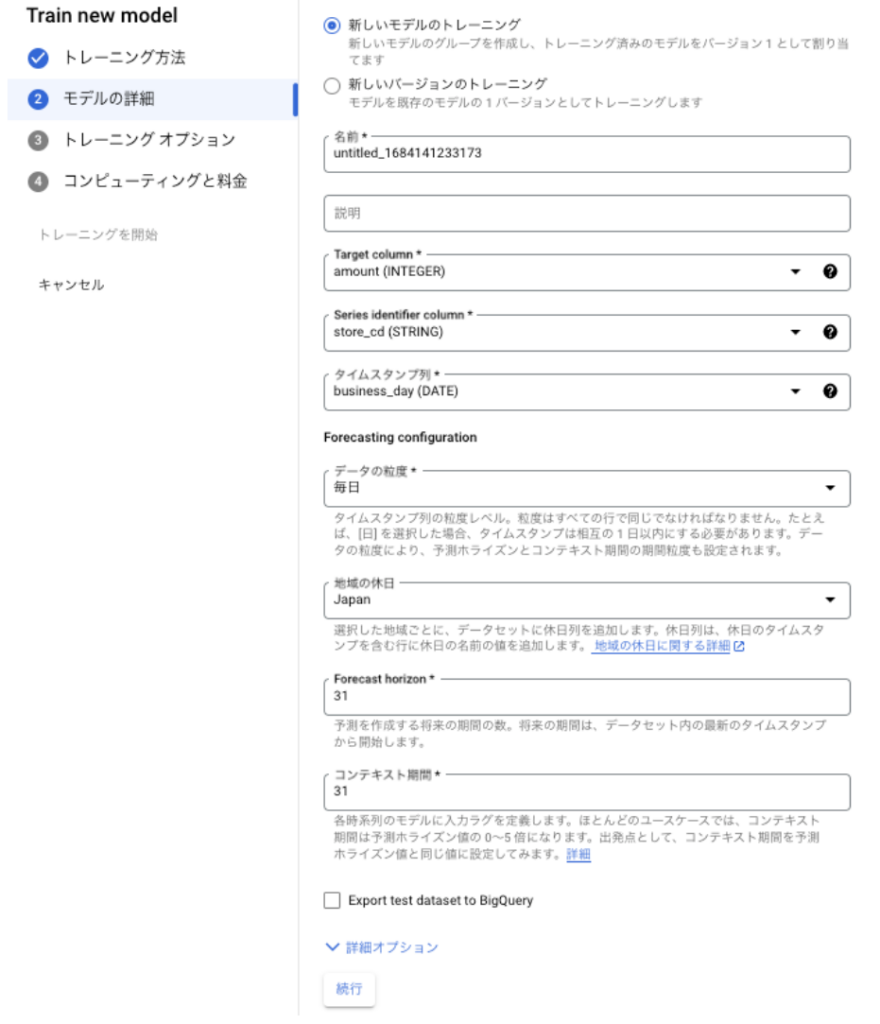
次に、「新しいモデルのトレーニング」を選択し、
Target Column(ターゲット列)に amount(売上金額)、Series identifier column(時系列識別子)に store_cd(店舗コード)、タイムスタンプ列に business_day(営業日)を指定します。
データの粒度は日別なので「毎日」、地域の休日は「Japan」、Forecast horizon は予想したい期間です。今回は5月なので31日とします。
コンテキスト期間は、いろいろ試しましたが、Forecast horizon と同じ値でOKです。コンテキスト期間について、もっと詳しく知りたい方は別記事「Vertex Forecast のコンテキスト期間、重み、階層予測などを徹底解説」をご参照ください。
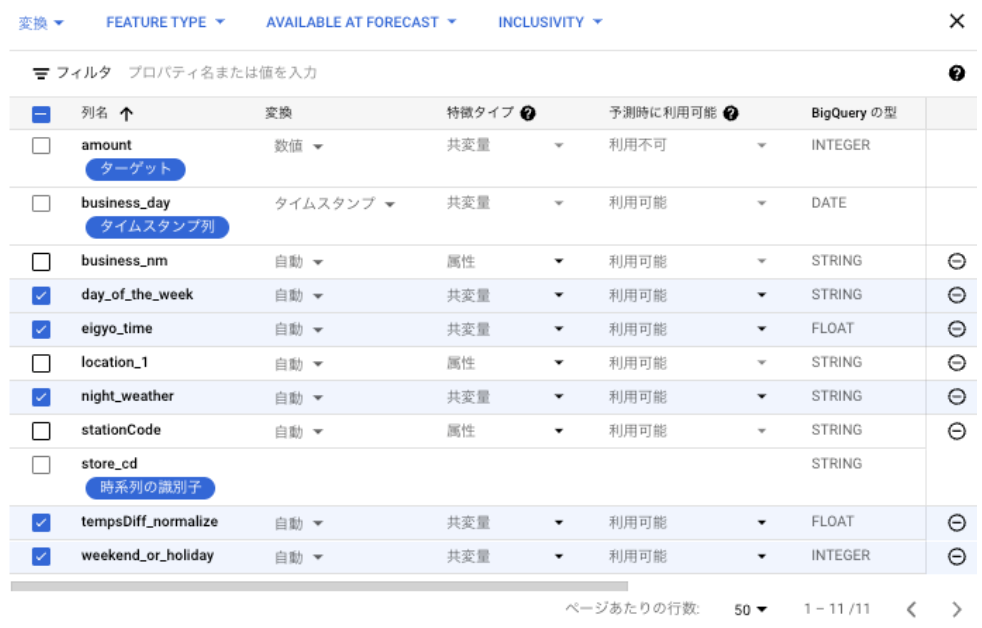
※BigQueryではカラム名は英語のみのためキャプチャは英語表記になっています。
トレーニングオプションは、特徴タイプだけ入力すればOKです。
特徴タイプには「属性」と「共変量」があります。
属性とは、時系列の期間中に変化しない静的な機能です(たとえば、アイテムの色や商品の説明など)。
共変量とは、時間の経過とともに変化することが見込まれる外生変数です(たとえば、天気予報、休日、遅延値など)。
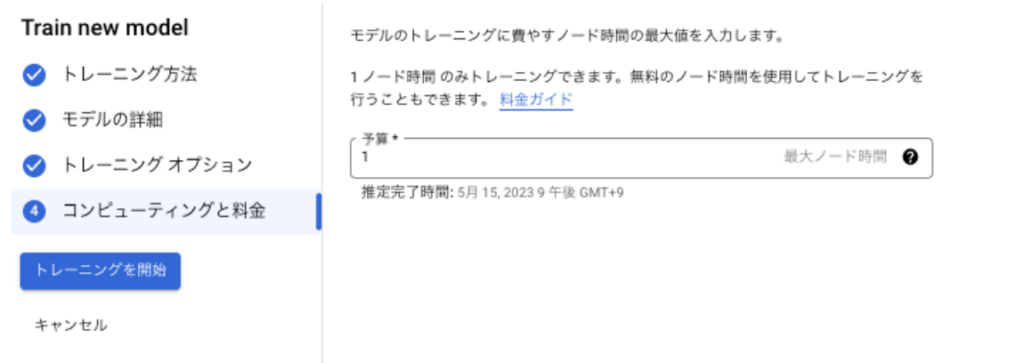
コンピューティングと料金の予算は「1」を入力。
トレーニングを開始で、トレーニング(モデル作成)が開始されます。
データ量にもよりますが、大体2〜2.5時間くらいかかります。
トレーニングが終わったら、Vertex AI からメール通知がきます。
リンクをクリックするとモデルの詳細画面に飛びます。Vertex AIのメニューから「Model Registry」でいつでも確認することができます。
以下はモデルの詳細、評価画面です。
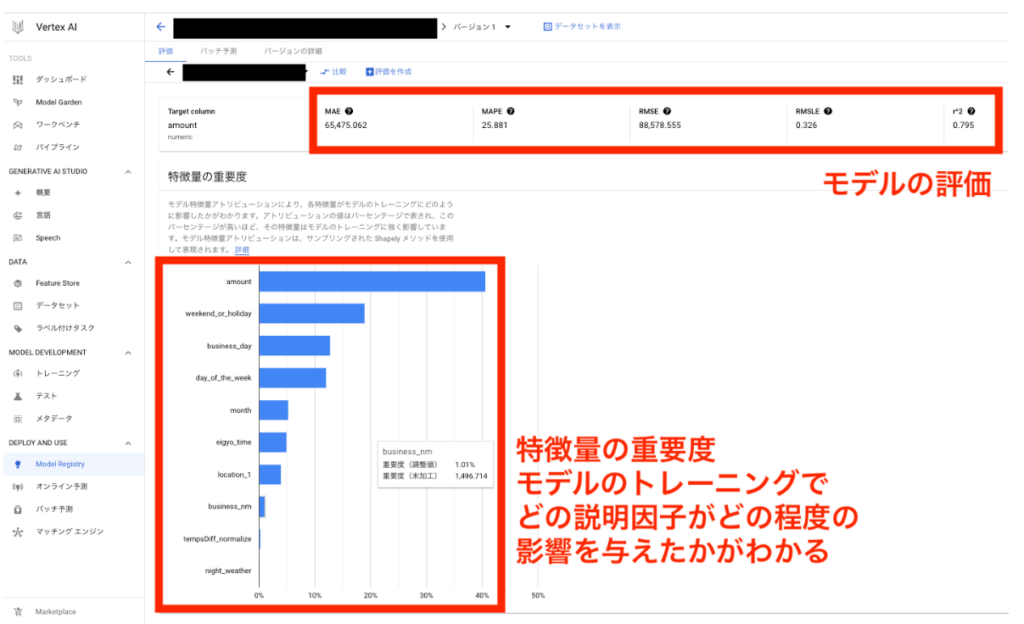
通常、時系列モデルの評価に r^2 は使わないのですが、AutoML Tableなど他のアルゴリズムで作られたモデルもここで参照するため、一通りの評価指標が表示されているようです。
ちなみに、時系列モデルの評価なら、この中ならMAEをみておけばいいかなと思います。
下の、特徴量アトリビューション(特徴量の重要度)は、モデルのトレーニングにおいてどの説明因子がどの程度の影響を与えたかを%で示してくれたものです。
キャプチャの例では amount(売上金額=ターゲット列)が最も強く、次に強いのは weekend_or_holiday(休日祝日フラグ)ということが読み取れます。
売上金額を予測するのに、最も強い因子は過去の売上金額で、その次が休日祝日かどうか、なのでまぁ納得感はあると思います。このレベルだとそりゃそうだ、で終わるかもしれませんが、説明因子がたくさんあるような場合はこのように影響度がわかると重宝します。
長くなってしまったので続き(②バッチ予測、③予実比較・評価)は次回!
API ARIMA AutoML Bard BigQuery Bing ChatGPT Cloud Endpoints Cloud Storage DWH EBPM GAS Generative AI Google Apps Script Google Cloud Google Form Google Workspace IT組織 Outlook PaLM PDF Python ReportLab selenium Statsmodels STL VertexAI Vertex Forecast スクラッチ セミナー ソトミル トレンド分析 トレーニング バッチ予測 世界は女性とデジタルが救う 女性活躍 技術 時系列データ分析 業務効率化 機械学習 特徴量エンジニアリング 生成AI 自動化 評価指標 需要予測