
こんな人の役に立つかも
- ChatGPTを仕事で使いたい
- 社内システムを使わずにデータベースの情報を参照したい
- 事務作業を効率化したい
ChatGPTって便利だけど、業務(仕事)では使えないんだよね〜、と残念に思っていませんか。
ChatGPT をはじめとした Bing や Bard など、オープンなチャットベースの生成 AI サービスは、一般公開されている情報を扱って回答を生成します。当然、社外秘のデータにアクセスできないため、社内の情報を使った資料作成やデータ参照はできません。この時点で、活用シーンはかなり限定的になります。
さらには、ユーザーが入力した質問を基盤モデルの学習に利用してしまうサービスもあり、社内での生成AI の利用自体、禁止・制限している会社が大多数ではないでしょうか。
今回、社内DBや機密情報に安全にアクセスして応答してくれるチャットツール「ソトミルチャット」を開発しましたので、ご紹介させていただきます。
社内DBの情報から回答を作る「ソトミル.チャット」
ソトミル.チャットは、社内の業務効率化に役立つサービスとして開発しました。
業務担当者は、ソトミル.チャットを利用することで、社内DB や機密情報に簡単かつ安全にアクセスし、質問や問い合わせをすることができます。これにより、担当者は、時間と手間をかけて調べる必要がなく、業務に集中することができます。
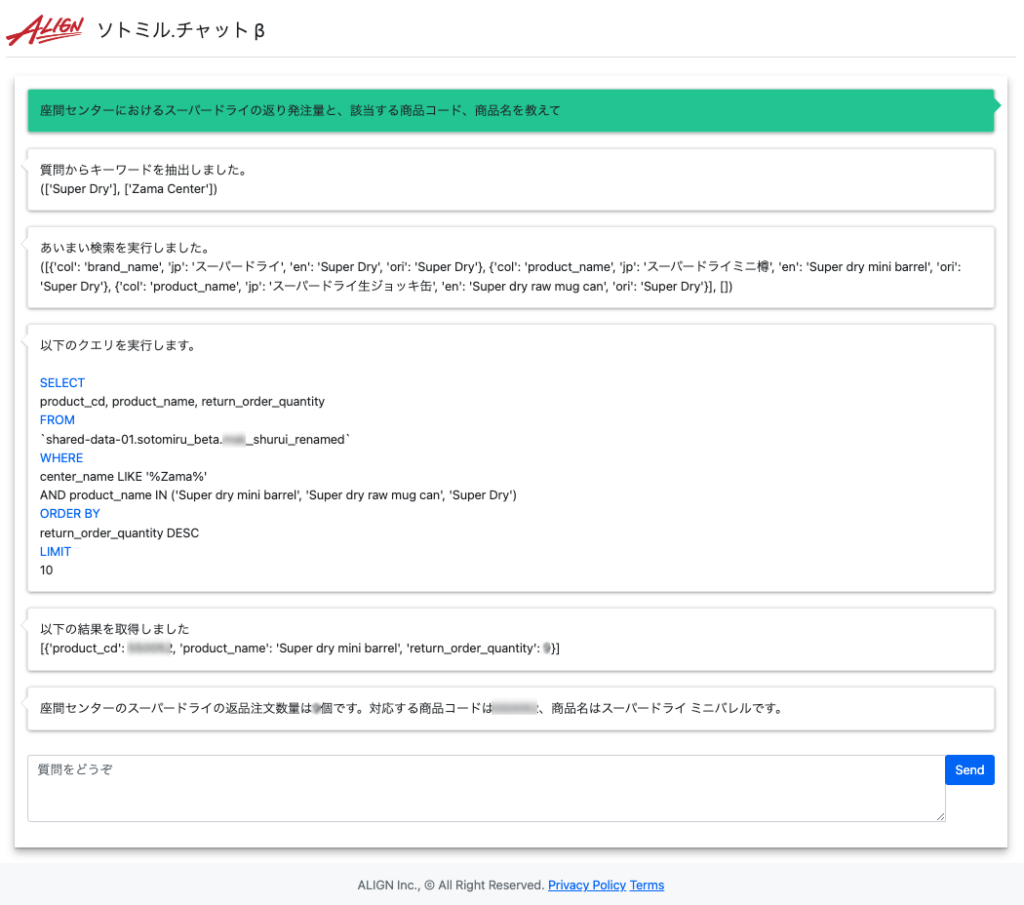
<主な特徴>
- チャット形式で社内DBや機密情報に関する問い合わせができる
- 社内DB に予測値があれば、発注業務における欠品アラートをあげることもできる
- 社内DB に該当データのない質問には、汎用的な大規模言語モデルとして回答する
- 抽出キーワード、生成したクエリ、実行結果など、途中経過を出力するため、回答の確らしさを確認できる
ソトミル.チャットが安全な理由
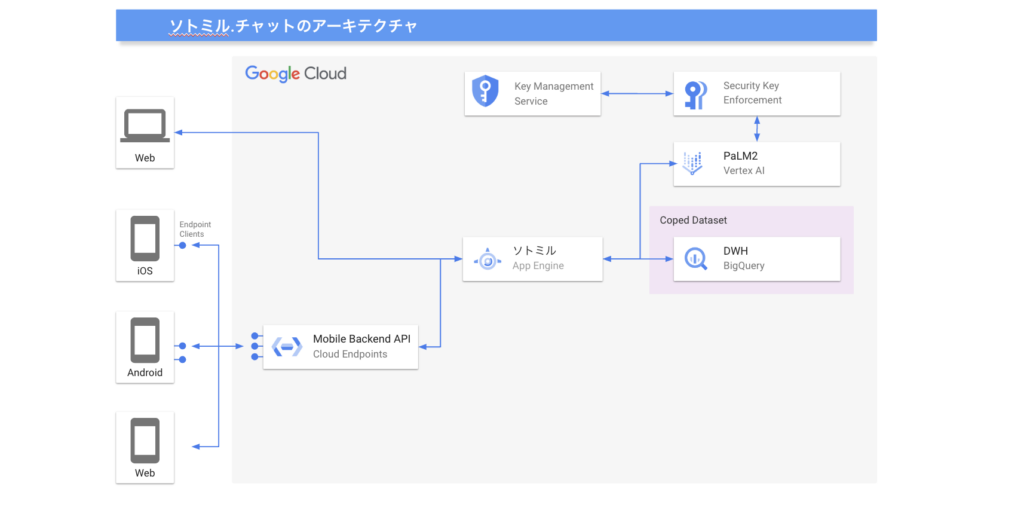
ソトミル.チャットの基盤モデルには Google 社の Vertex AI で提供されている PaLM 2 を利用しており、質問を含むすべてのデータは暗号化され、基盤モデルに入力されて応答が生成されます。また、基盤モデルのトレーニングにデータが使用されることはありません。
社内DBなどの機密情報や社外秘のデータには、ソトミル.チャット(クローズドな WEBアプリケーション)を介してアクセスを行うため、基盤モデルから直接アクセスされることはありません。
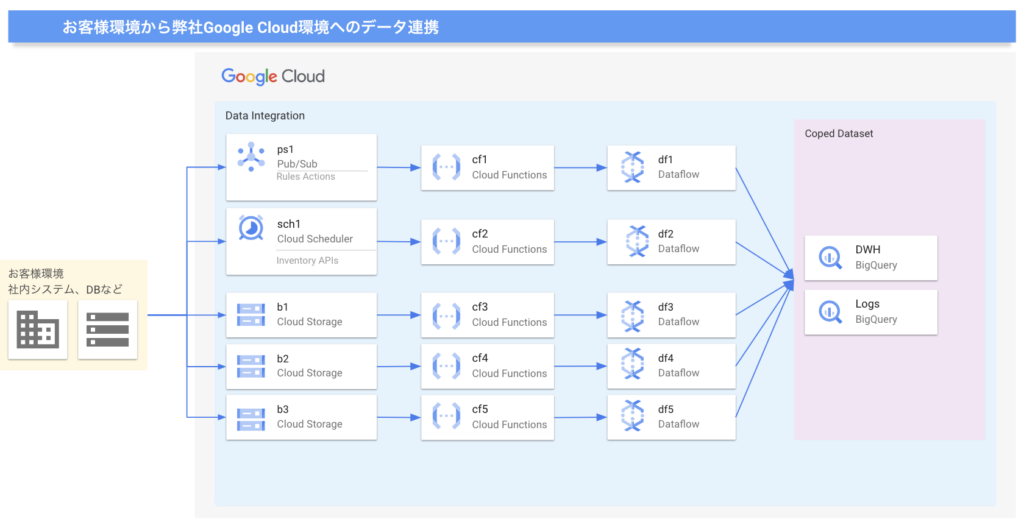
以下の図では、BigQuery が社内DB に該当します。

基盤モデルは、ユーザの質問からキーワードを抽出したり、アプリが取得したデータベースのスキーマ情報をもとに、クエリ(SQL)を生成するために利用しています。
作成されたクエリは、アプリを介してクローズドな環境で実行されます。
今回リリースしたベータ版では、問い合わせ先の社内DBにあるのは出荷実績のみですが、AI予測などと組み合わせることで、欠品アラートとして利用することもできます。
例えば、発注業務担当者が「来週の□□センターの商品〇〇について、△個発注しようと思うけど、欠品する可能性はどれくらい?」などの問い合わせが可能になります。
他にも、接続先DBを変更、拡張していくことで、広がりのあるサービスになるのではないかと思っています。
導入後のアーキテクチャ例
まず、検索対象のテーブルをどう作るか。これは、お客様の社内DBに直接アクセスすることはせず、弊社Google Cloud環境にオリジナルのデータをバッチ、CSVファイルをバケットに格納してもらう等、なんでもいいのですが連携してもらい、BigQueryにコピーします。コピーしたデータを使って検索対象のテーブルを自動生成します。ここで、翻訳テーブルなども作ってしまいます。
次に、アプリケーション(ソトミル.チャット)をお客様に合わせてカスタマイズし、App Engin にデプロイします。これにより、ブラウザからアクセス可能な Webサービスとして利用できるようになります。利用者は、ログインして利用を開始できます。ご希望なら、モバイルからの利用も可能です。
ソトミル.チャット開発の裏話
開発で一番苦労したのは、質問で入力された日本語の名称(商品名など)をどうやってDBに当てるか、という点です。
将来的には PaLM2 側でアップデートが入って解消されると思いますが、現在(2023/8/2時点)は PaLM API もベータ版であり、対応言語は英語のみです。この関係で、アプリ側で処理の入口と出口で翻訳を行っているのですが、質問に業界特有の用語や商品名などを含めると、翻訳で失敗してしまうケースが大半でした。
例えば、名称がなんの名称なのか判別できないため、商品名をメーカー名として検索してしまう、ということが起きました。
<名称がなんの名称なのか判別できない問題>
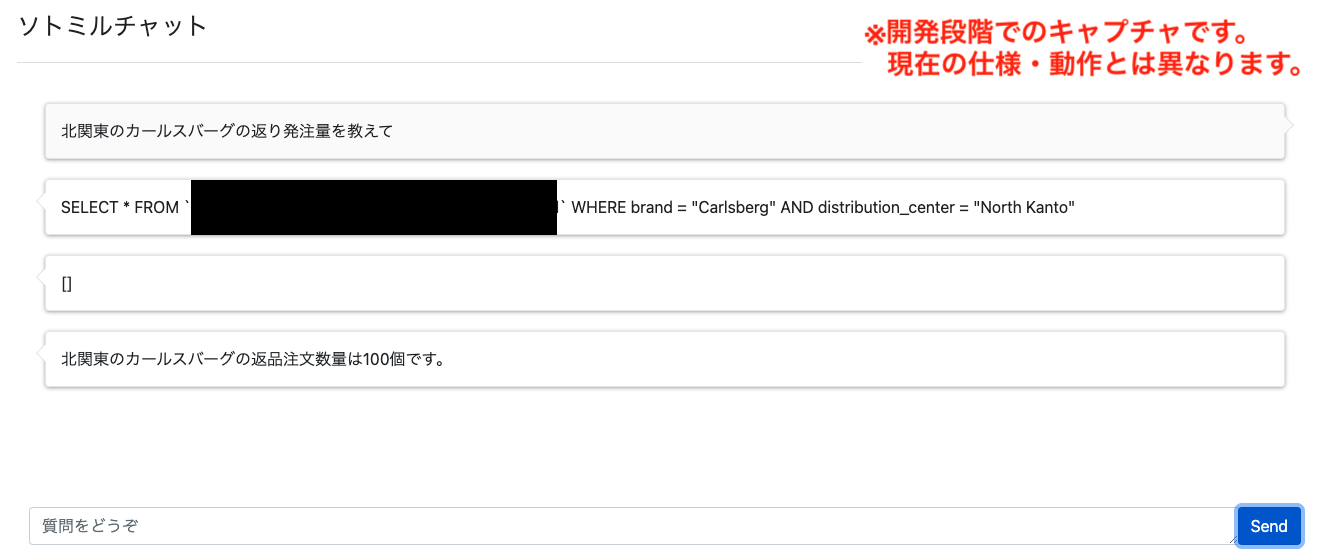
開発初期段階では、翻訳した質問とスキーマ情報だけを PaLM 2 に与えてクエリを生成してもらっていたのですが、上のキャプチャのように、生成したクエリではカールスバーグ(ビールの商品名)がブランド名(brand)として検索されてしまっています。
この問題に対して、質問に含まれる商品名などの名称(キーワード)を PaLM 2 に抽出してもらい、クエリを生成する前に各種マスタへの横断的なあいまい検索を行うように処理を追加したところ、クエリ生成の精度がかなりよくなりました。
他にも、一部の商品については、文脈によって商品名の翻訳が変わってしまう問題があります。
<翻訳の問題>
- 金麦 → golden wheat
- 金麦琥珀の秋 → Kinmugi Amber Autumn
この問題は、ソトミル.チャット専用の翻訳マスタをメンテすれば対応可能です。ゆくゆくは、お客様の方でも辞書登録していただけるよう、メンテ用の画面機能を追加リリースしたいと考えています。
まだ課題は多いですが、うまく育てていければ、お客様の業務効率化に役に立つサービスになるのではないかと思っています。
もし、この記事を読んでご興味を持っていただけた方は、お気軽にお問い合わせください。
まとめ
- ソトミル.チャットの生成AIの基盤モデルは Google 社の PaLM 2
- ChatGPT とは異なり、質問を含む全てのデータはアップロードの際に暗号化され、無断で学習に利用されることもない。
- PaLM 2 が直接社内DB にアクセスすることはなく、社内DBやそれに類する環境へのアクセスはアプリ(ソトミル.チャット)が行う。
- PaLM 2 の役割は主にクエリ生成で、クエリの実行はアプリが BigQuery API を介して行う。
<関連リンク>
Vertex AI におけるデータガバナンスと生成 AI(公式)
アライン株式会社、生成AIチャットサービス「ソトミル.チャット」を提供開始
API ARIMA AutoML Bard BigQuery Bing ChatGPT Cloud Endpoints Cloud Storage DWH EBPM GAS Generative AI Google Apps Script Google Cloud Google Form Google Workspace IT組織 Outlook PaLM PDF Python ReportLab selenium Statsmodels STL VertexAI Vertex Forecast スクラッチ セミナー ソトミル トレンド分析 トレーニング バッチ予測 世界は女性とデジタルが救う 女性活躍 技術 時系列データ分析 業務効率化 機械学習 特徴量エンジニアリング 生成AI 自動化 評価指標 需要予測