
ある仕事の中で、100万行近くあるCSVファイルをアップロードする必要がありました。
一度に処理すると色々不便だったので、CSVファイルを分割するコードを書いてみました。
というわけで、今回は「Pythonを使って大容量のCSVファイルを分割する方法」についてご紹介したいと思います。
処理の手順
処理の流れは以下の2つだけ
① CSVデータを10万行ずつ分割して読み込み
② 分割したデータをそれぞれCSVファイルとして新に出力
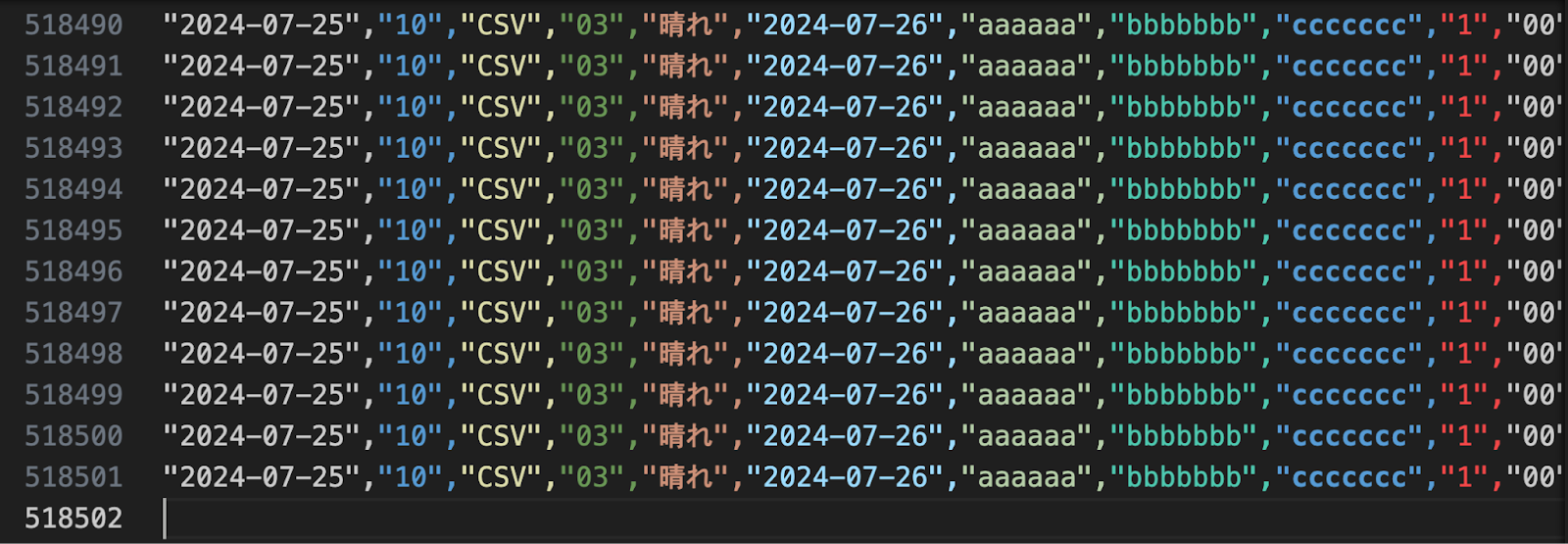
以下のような約52万行のダミーデータを分割してみたいと思います。
CSVを分割するコード
ファイルのサイズごとに分割するなど他にも方法はありますが、今回は単純に行数を指定する方法です.。
pandas.read_csvメソッドを使用して、chunksizeパラメータに指定した行数ごとにファイルを読み込みます。
import pandas as pd
# CSVファイルのパスを設定
csv_file_path = 'sample_data.csv'
# 分割のための行数を指定
chunk_size = 100000 #10万行ずつ分割
# 指定した行数ごとにファイルを読み込む
chunks = pd.read_csv(csv_file_path, chunksize=chunk_size)
for i, chunk in enumerate(chunks):
# 新しいCSVファイルとして保存
chunk.to_csv(f"./output/chunk_{i}.csv", index=False)たった数行の短いコードで、分割できました!
実行結果
outputフォルダに、6つに分割されたCSVファイルが格納されています。
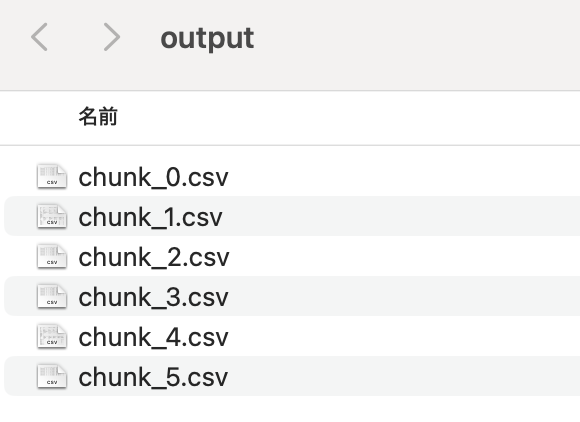
▼ chunk_0.csv
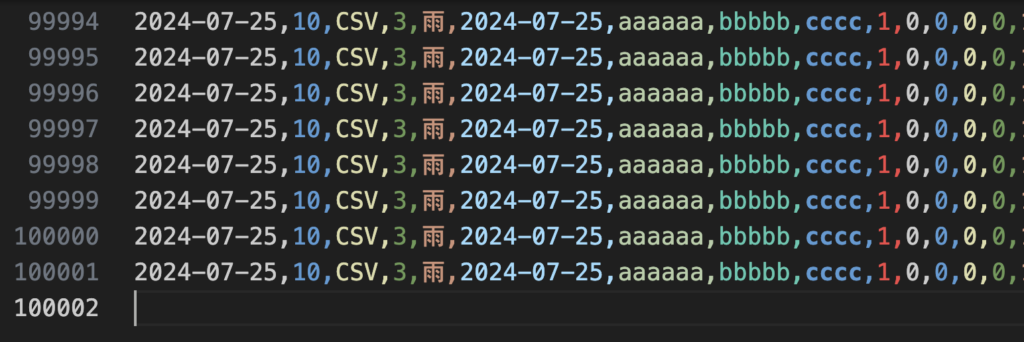
▼ chunk_5.csv
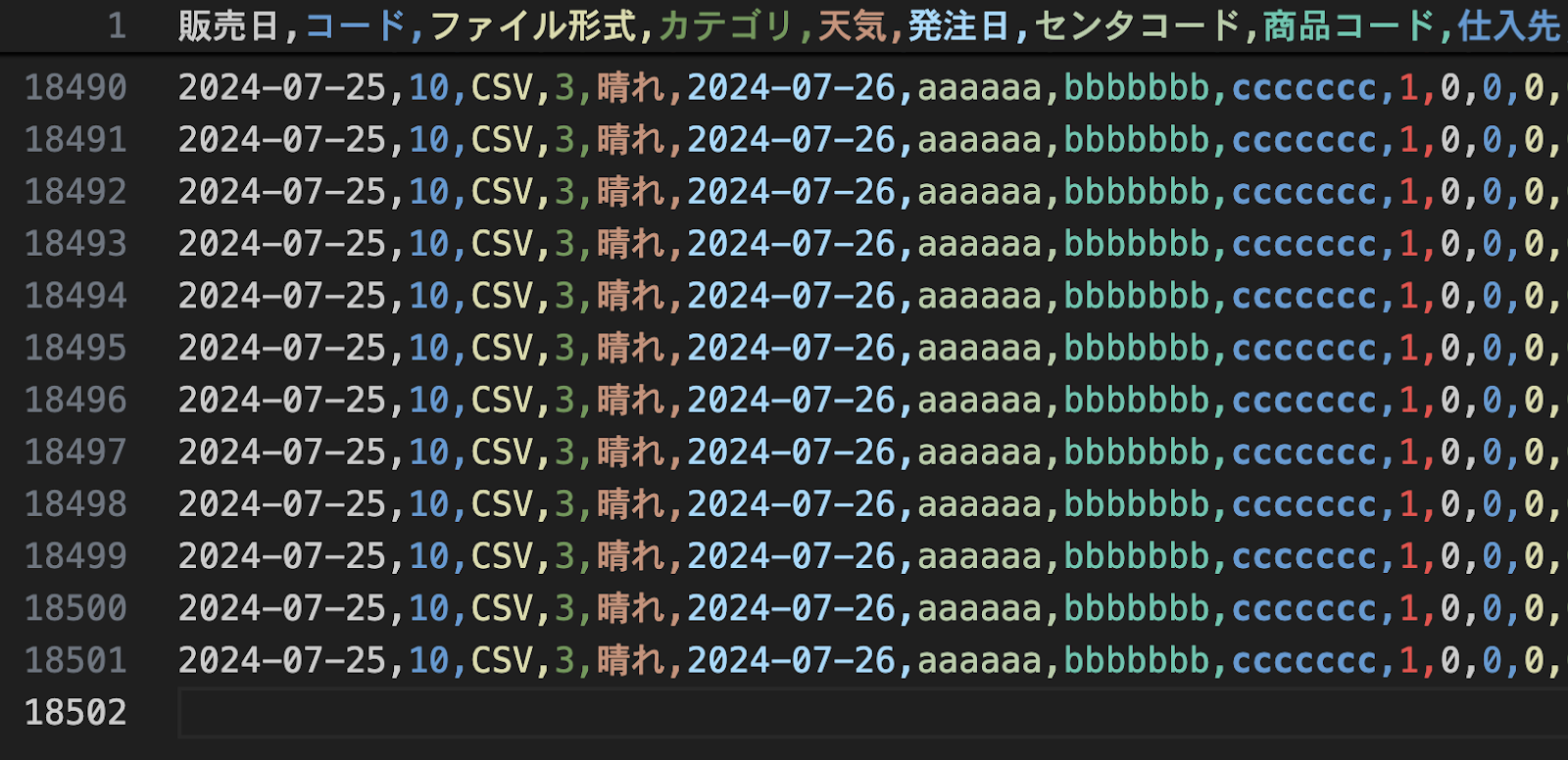
ヘッダーも込みで出力されています。
100万行のCSVファイルをEXCELやメモ帳で開くとフリーズしたり、、、プログラム上で一括で処理をしようとすると負荷がかかって何かと面倒ですが、CSVファイルを分割すれば扱いやすくなりました。ひと工夫するのは大事ですね!
以上、大容量のCSVファイルを分割する方法でした。
まとめ
- 大容量のCSVファイルは「chunksize」を指定して分割
- ひと工夫すると負荷も軽減され時間も節約
API ARIMA AutoML Bard BigQuery Bing ChatGPT Cloud Endpoints Cloud Storage DWH EBPM GAS Generative AI Google Apps Script Google Cloud Google Form Google Workspace IT組織 Outlook PaLM PDF Python ReportLab selenium Statsmodels STL VertexAI Vertex Forecast スクラッチ セミナー ソトミル トレンド分析 トレーニング バッチ予測 世界は女性とデジタルが救う 女性活躍 技術 時系列データ分析 業務効率化 機械学習 特徴量エンジニアリング 生成AI 自動化 評価指標 需要予測