
データをもらったはいいけど
・大量すぎて自社環境に移せない
・ローカルでは解凍しきれない
・手作業でアップするには時間も手間もかかりすぎる
など困ったことはありませんか。
弊社でも先日とある PoC 案件で、Google ドライブ経由で大量の分割 zip ファイルを含む複数回圧縮されたPOSデータを受領しました。解凍するとファイル数は数百、データサイズは TB になるため単純な手作業での解凍やアップロードは現実的ではありません。
今回はこのような大量のデータを Google Cloud の BigQuery に一括解凍&ロードする方法をご紹介したいと思います。
<やったこと>
- Googleドライブで、10GB 程度まで複数回圧縮された .7z ファイルを複数受領
- ローカルにダウンロード
- 最終 zip まで解凍
- ファイル名を日本語から英語に一括置換
- 数 GB になるよう圧縮し直して GCS(Google Cloud Storage)にアップロード
- Dataflowで GCS → GCS に一括解凍
- Dataflowで GCS → BigQuery に一括ロード
圧縮元の CSV、ZIP ファイル名が日本語だったり、2重、3重、4重と何度も圧縮されていたこともあり、上記3〜4のローカルでの手作業が発生してしまいました。が、csv まで展開する必要はなかったので、重すぎてフリーズすることもありませんでした。
Google Cloud にアップした後は、サクサク〜っと終わりました。
目次
ローカル PC での作業
この部分↓の具体的なやり方について説明します。
- 最終 zip まで解凍
- ファイル名を日本語から英語に一括置換
- 数 GB になるよう圧縮し直してGCS(Google Cloud Storage)にアップロード
今回受領したのは4重に圧縮された POS データ。
1ファイル 5GB ほど CSV ファイルが圧縮されて1ファイル 250MB の zip ファイルになっており、その zip ファイルが 100 個くらいずつさらに圧縮されており、それがさらに圧縮された 7z 形式のファイル(約 10GB )として受領しました。
私が使っている Macbook air のストレージ(Macintosh HD)は 500GB なので、これを超えない程度に、数回に分けて「解凍→ファイル名の一括変更→圧縮」をしました。
少しずつローカルで解凍し、zipファイル名の日本語部分を英語に変更し、再圧縮(.zip)しました。さすがに全部を Macbook air 上で解凍できないので。
ちなみに Mac でファイル名を一括置換する方法は以下の通りです。(下図)
<Mac でファイル名を一括置換する>
Finder > 複数ファイル選択状態で右クリック > 名称変更)

一括置換された!

後は、これを再圧縮して GCS にドラッグ&ドロップでアップロードするだけです。
まとめると、受領時は4回圧縮で 7z 形式だったのが、最終的にアップロード時には3回圧縮で zip 形式(ファイル名は英語)の状態にしました。
圧縮に圧縮を重ねた TB(テラバイト)データを一括で解凍する Dataflow の神テンプレート
6. DataflowでGCS→GCSに一括解凍
Dataflow とは、Google Cloud のサービスの一つで、その名の通りデータをある場所からある場所に流してくれます。テンプレートが用意されているので、利用者は基本的にコンソール上でボタンをポチポチするだけでデータパイプラインの構築ができてしまいます。
例えば、GCS → BigQuery にデータを流し込みたい時は Cloud Storage Text to BigQuery パイプライン を使います。他にも、BigTable、Spanner、Elasticsearch、MongDB、Pub/Sub などに対応したテンプレートも用意されており、バッチでもストリーミングでもできちゃうスグレモノ。
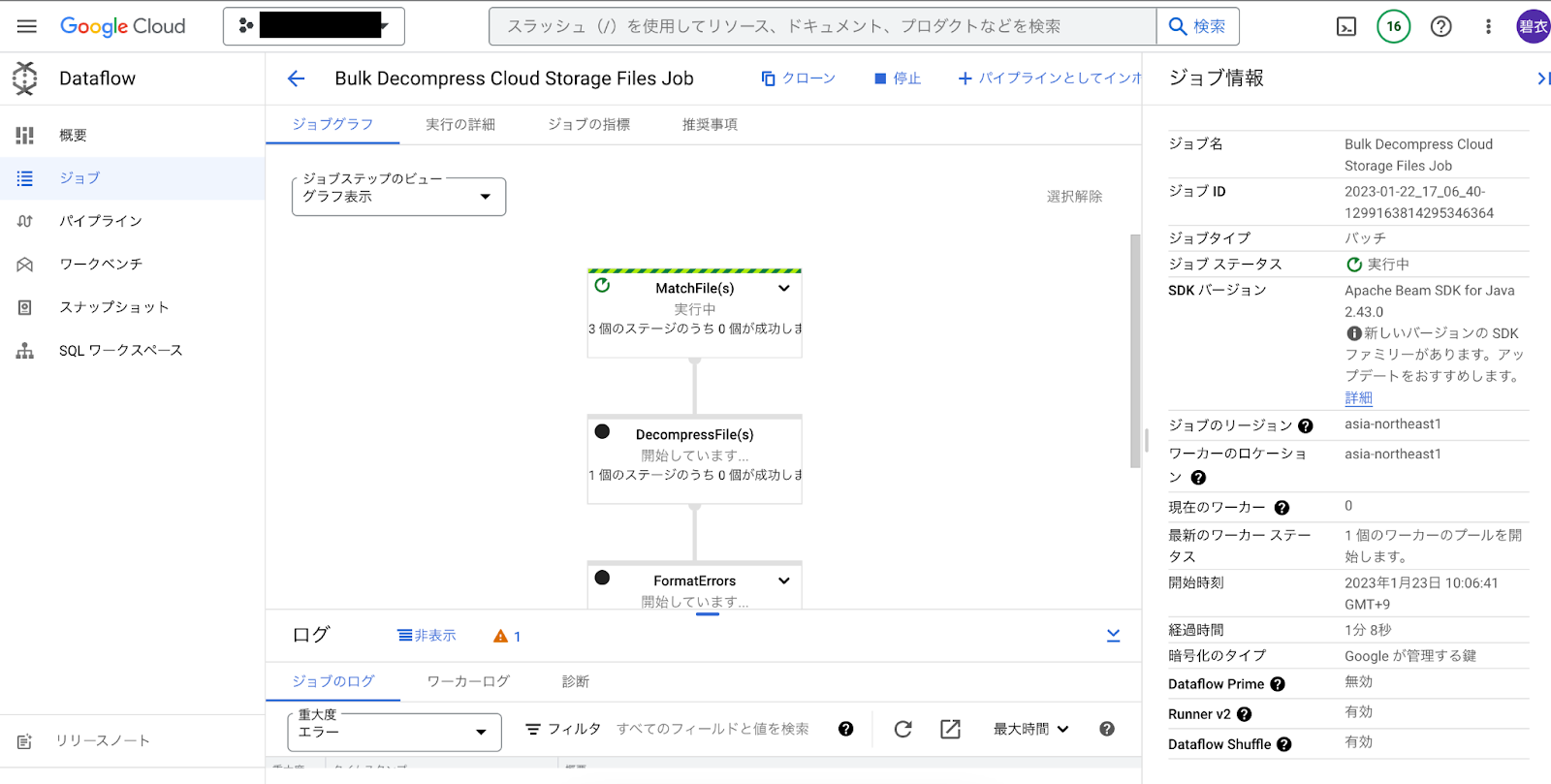
今回、複数回圧縮された zip ファイルを一括解凍するために使ったテンプレートは Bulk Decompress Cloud Storage Files パイプライン です。
<GCS上の zip ファイル群を一括解凍する Dataflow>
Google Cloud コンソール > Dataflow > テンプレートからジョブを作成

必須パラメータを入力していきます。
あらかじめインプット、アウトプット用のバケットを GCS に用意しておきます。
ジョブ名:なんでも
リージョン エンドポイント: GCSバケットと同じリージョン
Dataflow テンプレート: Bulk Decompress Cloud Storage Files
必須パラメータ
The input filepattern to read from: gs://input_bucket/*.zip
The output location to write to: gs://output_bucket
The output file for failures during the decompression process: gs://output_bucket/decompressed/failed.csv
一時的な場所: gs://output_bucket/temp
後は「作成」ボタンを押すだけ!
実行中…
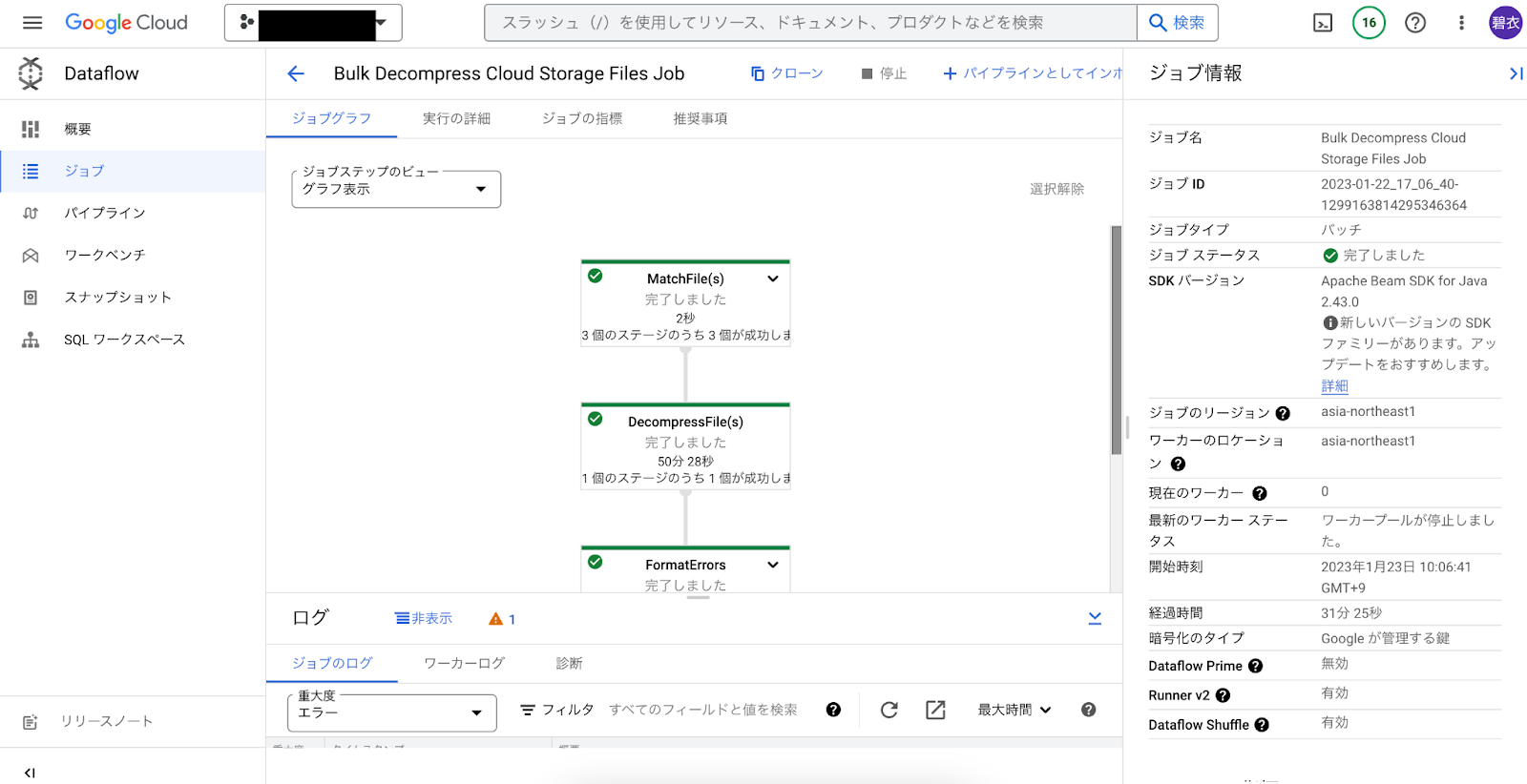
1TB の圧縮データの解凍/展開が 31分で完了しました。ローカルで解凍してアップしていたら何年かかるか分かりませんので、これはありがたい!
ノーコードなのでお手軽なのも最高でした。
なお、zip ファイル名(あるいは Bzip2、Deflate、Gzip)に日本語が含まれていると以下のようなエラーになりますのでご注意ください。
<エラー内容>
Error message from worker: java.lang.RuntimeException: org.apache.beam.sdk.util.UserCodeException: java.lang.IllegalArgumentException: malformed input off : 3, length : 1 org.apache.beam.runners.dataflow.worker.GroupAlsoByWindowsParDoFn$1.output(GroupAlsoByWindowsParDoFn.java:187)
日本語名称のファイルを Windows 上で zip にすると、MS932 やら Shift-JIS やらになってしまうみたいです。ニホンゴムズカシイ。対処法は、zip ファイル名を英語にして圧縮し直して GCS にアップし直す、です(前述の手順3〜5を参照)
GCS 上の CSV ファイル群を一括で BigQuery に取り込む
7. Dataflowで GCS → BigQuery に一括ロード
無事、GCS のバケットに展開されたCSVファイル群がある状態になりました。
またまた Dataflow で、今度は GCS → BigQuery のテンプレート(バッチ)を使って BigQuery に流し込みます。
Cloud Storage Text to BigQuery パイプライン
用意するのは、取り込み用スクリプト、スキーマ定義 JSON です。
取り込み用スクリプト(transform.js)
| function transform(line) { var values = line.split(‘,’); var properties = [ ‘store_cd’, ‘store_nm’, ‘business_cd’, ]; var fixedData = {}; for (var count = 0; count < values.length; count++) { if (values[count] !== ‘null’) { fixedData[properties[count]] = values[count].replace(/”/g, “”); if (values[count] == ‘”NaN”‘) { fixedData[properties[count]] = values[count].replace(‘”NaN”‘, ”); }else if(values[count] == ‘”null”‘){ fixedData[properties[count]] = values[count].replace(‘”null”‘, ”); } } } var jsonString = JSON.stringify(fixedData); return jsonString; } |
スキーマ定義 JSON(schema.json)
| { “BigQuery Schema”: [ { “name”: “store_cd”, “type”: “STRING”, “mode”: “NULLABLE”, “description”: “店舗コード” }, { “name”: “store_nm”, “type”: “STRING”, “mode”: “NULLABLE”, “description”: “店舗名” }, { “name”: “business_cd”, “type”: “STRING”, “mode”: “NULLABLE”, “description”: “業態コード” } } |
ファイルを作成したらそれぞれ所定の GCS バケットにアップしておきます。今回は下記にアップしました。
gs://output_bucket/dataflow/
<GCS 上の csv ファイル群を一括で BigQuery にロードする Dataflow>
Google Cloudコンソール > Dataflow > テンプレートからジョブを作成

ジョブ名: なんでも
リージョンエンドポイント:GCS バケットと同じ
Dataflow テンプレート: Text Files on Cloud Storage to BigQuery ※バッチの方を選択する
必須パラメータ
JavaScript UDF path in Cloud Storage: gs://output_bucket/dataflow/transform.js
JSON path: gs://output_bucket/dataflow/schema.json
JavaScript UDF name: transform ※fanction名
BigQuery output table: project_id:dataset_id.table_name
Cloud Storage input path: gs://output_bucket/*.csv
Temporary BigQuery directory: gs://output_bucket/dataflow/temp_dir
一時的な場所: gs://output_bucket/dataflow/temp_dir
実行中…

成功!

またまた 31 分で完了。
…!?

この記事は全て終わった後で書いているのですが、実際の作業では一度もCSVまで解凍せずにBigQueryまでロードしたので、ここに来てようやく受領したデータのトータルサイズが 1.68 TB だったことがわかり、結構驚きました。
テラバイトデータでも Google ドライブ経由で受け渡しできちゃうんだな〜と改めて感心。
BigQueryで確認してみる、、、

……….!?

8億件ありました。しゅごい。。。
ホント、便利な世の中になりました。
まとめ
- 複数回圧縮された大量の分割zipファイルでもDataflowのテンプレートを使えば、GCS上で一括解凍できる
- Dataflow には様々なテンプレートが用意されており、ほぼノーコードでデータパイプラインを構築できる
- 日本語ファイル名で圧縮をかけると文字コードがShiftJISに変わってしまうことがあるので注意
【編集後記】データの企業間での受け渡し、正直しんどいAPI
最も安全な方法は専用のAPIを作ってしまうことだと思いますが、構築に時間がかかるのと、セキュリティ面で、認証を通すなど相手企業にも何度もやりとりをお願いせねばならずハードル高めです。
本稼働が決まり定期的にデータのやりとりが発生するならアリですが、普通はいきなりそういう契約にはならず、前段階としてPoCで、お試し、様子見期間を設けます。じゃあ、まずはサンプルデータを、という話になりますが、サンプルデータがすでにちょっとしたビッグデータなケースも AI の世界では全然あると思います。(ちなみに、総務省によると「ビッグデータ」と呼ぶのは数十テラバイトから数ペタバイトに及ぶ範囲とのこと)
セキュリティ的にはあまり推奨されませんが、DB から抜いてもらったデータを圧縮ファイルにしてメール添付なり Google ドライブにアップなりして渡してしまうのがお互い最も負担が少ないのも事実です。
これまで、ここまで大量のデータを圧縮ファイルで受領したことはありませんでしたが、 PoC で単発の可能性があったり、あまり時間がない時などはこういう受け渡しも、個人的には全然アリかなと思いました。
API ARIMA AutoML Bard BigQuery Bing ChatGPT Cloud Endpoints Cloud Storage DWH EBPM GAS Generative AI Google Apps Script Google Cloud Google Form Google Workspace IT組織 Outlook PaLM PDF Python ReportLab selenium Statsmodels STL VertexAI Vertex Forecast スクラッチ セミナー ソトミル トレンド分析 トレーニング バッチ予測 世界は女性とデジタルが救う 女性活躍 技術 時系列データ分析 業務効率化 機械学習 特徴量エンジニアリング 生成AI 自動化 評価指標 需要予測